{date: 201125}
I have talked and written about FScape multiple times now. It is the oldest (ca. 2001–) software I created that I consider a “serious” experimental sound software. I also keep coming back to it. There was something of a simplicity in it that allowed many people to quickly get started, and so it is also the software I receive the most feedback from, as people write to me from time to time, speak a compliment or ask a question.
The source code is “brute” in a way, a plain imperative Java code that reads sound files, mangles data, writes sound files. There is no greater “form” in the sense of an underlying signal processing framework involved, it just is really plain operations. That is its beauty, but also makes it problematic, as I have moved to other questions and code style, and while I maintain the “classic” FScape program, I rarely add any new signal processing routines.
Instead I started to think that it would move the project forward, if I found an abstraction and framework to integrate it with SoundProcesses. The repository is called “FScape-next”, and it became something both similar and dissimilar to the classic program. It uses the UGen approach already employed by the real-time synthesis system within SP. Was this a good choice? A good choice would be one that both makes it possible to express most of the modules in FScape classic, while also bringing in a fundamental research layer that makes it a critical piece of software.
{group: fsc1, keywords: [_, experimental, simplicity, operation, beauty, style, UGen]}
The UGens are implemented on an asynchronous and hybrid push/pull streaming library (Akka Stream), and the behaviour is actually quite different from the synchronous API known from a real-time system such as SuperCollider server. Packets could arrive in different orders and frequencies, there is a nominal block size, but in principle block sizes and data rates can vary. For instance, take the UGen ResizeWindow(in, size, start, stop) that allows to resize packets (windows) of signals, essentially increasing or decreasing the data rate compared to other signals, or the UGen FilterSeq(in, gate) that retains only those elements in the stream for which the corresponding gate signal is positive. On the other hand, it feels like I'm still subjected to the linearity of the passage of time that is common to real-time processing. There is something missing, there is no good generally available random access mechanism (even though some UGens perform internal buffering and run random-acess operations).
Somehow I am hoping that this loss is compensated when UGens are more clearly typed (currently they support three different numeric types which are transparent to the user), and when a form of reset / reuse mechanism is introduced, so that more "procedural" code can be written.
On the right, that's how I sometimes sketch a small algorithm that I want to employ for a sound. This is from an ongoing electroacoustic composition Shouldhalde, and I have a section of one of its parts that I'm not happy with—the sound is still a quite raw microphone recording, you hear the acoustics of the studio, it produces the “wrong space” so to speak. I bounced the 8 minute section, and the idea is to reorder all the sound particles in it, in a variant of what in classic FScape is the StepBack module. That module does a segmentation of a sound, based on local minima in autocorrelation, and then reorders the segments in reverse order. What was developed in the sketch, can be easily formulated in language: Go through the sound. There is a minimum segment length, below which no cutting is down. After the minimum length has been reached, start cross-correlating the sound with “the remaining chunk” of the sound, stopping after a given maximum duration. Determine the local maximum of the cross-correlation; cut the sound here, and proceed by jumping to the correlation partner. “Remove” the parts of the sound which have been “used” so far, and repeat. That's a simple description, but difficult to formulate with the given UGen infrastructure. It requires structured data; for example, one has to maintain a list of regions of the sound that until now have not yet been used. After each step, the used region must be “removed” from that list. And we need random access to the sound. I could implement the whole algorithm as one new UGen. But that goes against the idea UGens as smaller reusable atoms instead of more complex compound algorithms.
{group: fsc1, keywords: [_, UGen, asynchronous, behaviour, signal flow, time, acoustics, electroacoustic, segmentation, auto-correlation, chunk, formulation], artwork: Shouldhalde}
There are three stategies then. First, consider the effort too high and uneconomic—the time away from the primary artistic process is too high, the risk is too high to lose the momentum on the artistic work; thus choose a different algorithm, or abandon the action, and turn to another action. Second, implement the algorithm in “plain code”, ignoring FScape and its current restrictions. That will cost a medium amount of time, the downside being that it will become a particular solution that can not be integrated with the existing code. Third, interrupt the work, and try to conceptualise and implement the necessary architectural changes to FScape. A bottomless pit.
{group: fsc2, keywords: [_, strategy, absence, abandon, implementation, interruption]}

With software written by yourself, there is ultimately only one instance to blame for its deficiencies. It never works to the full extent, so you have to live with this precarity.
{keywords: [imperfection]}
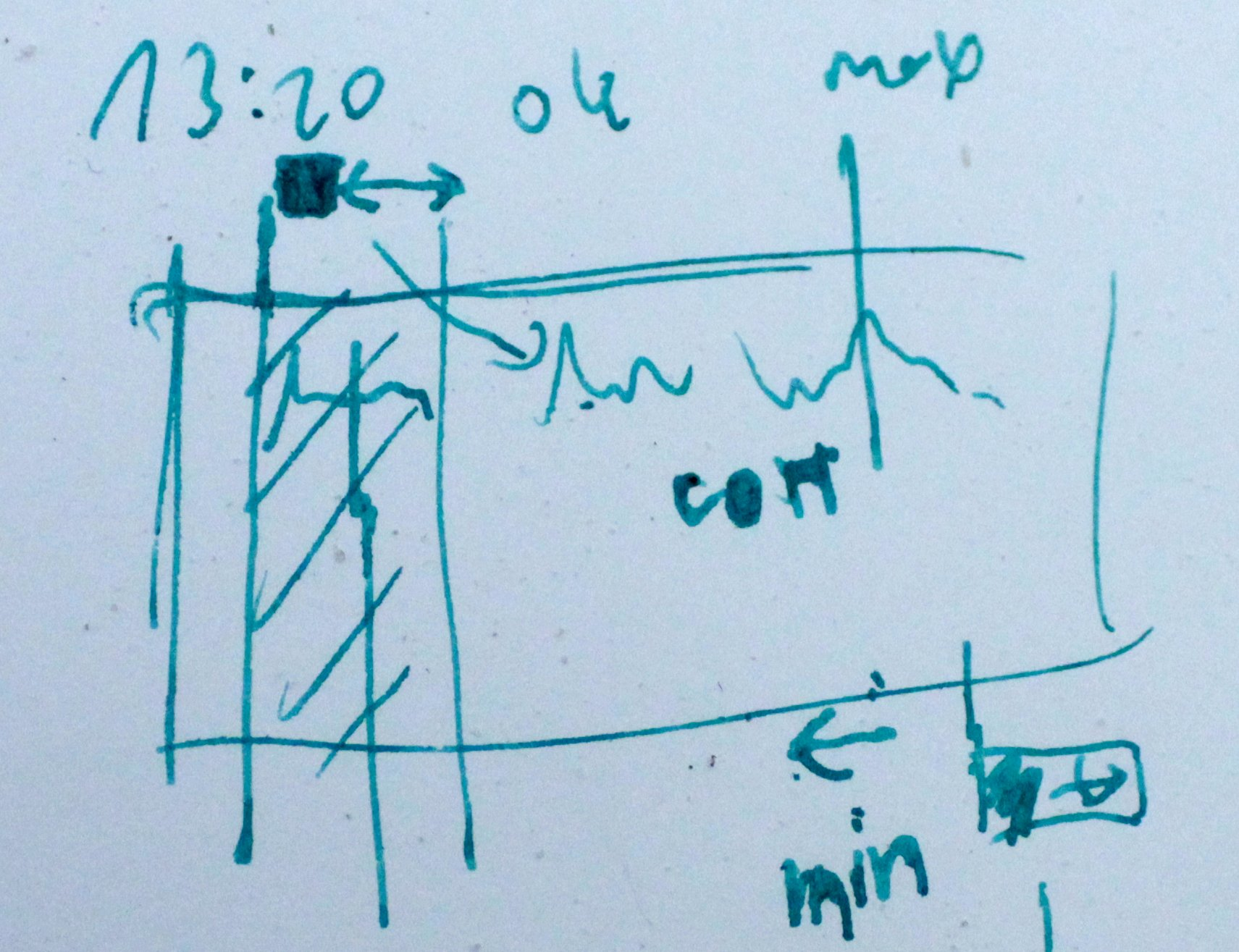
A fourth strategy is to work around with other abstractions already in SP. I could run one search iteration go in an FScape program, and then write an enclosing Control program that does the buffer erosion and re-runs FScape again and again. This is similar to the algorithmic loop employed in Writing (simultan).
{group: fsc2, artwork: WritingSimultan, keywords: [_, strategy, abstraction, buffer, loop]}
FScape code for a single iteration of searching within a given source span, for a destination span at a minimum given distance, that will maximise correlation.
{kind: caption, group: fsc3, keywords: [correlation]}
// version: 26-Nov-2020
val in0 = AudioFileIn("in")
val numFrames0 = in0.numFrames
val SR = in0.sampleRate
val numFrames = numFrames0.min((SR * 60 * 4).toLong)
def mkIn() = AudioFileIn("in").out(0)
val fftSize = 2048 // 1024 // 2048
val stepDiv = 1 // 4
val sideDur = "corr-len".attr(1.0) // 0.05
val numMel = 42
val numCoef = 21
val minFreq = 100.0
val maxFreq = 14000.0
val startSrcFr = "start-src".attr(0L).min(numFrames)
val srcLenSec = "dur-src".attr(10.0)
val srcFrames0 = (srcLenSec * SR).toInt
val stopSrcFr = (startSrcFr + srcFrames0).min(numFrames)
val srcFrames = stopSrcFr - startSrcFr
val destOffSec = "offset-dst".attr(2.0).max(0.0)
val destOffFr = (destOffSec * SR).toInt
val stepSize = fftSize / stepDiv
val sideFrames = (SR * sideDur).toInt
val sideLen = (sideFrames / stepSize).toInt.max(1)
val covSize = numCoef * sideLen
val srcLen = srcFrames / stepSize
// number of steps through the source
val srcNumM = (srcLen - sideLen).max(0)
val srcNum = srcNumM + 1
val inLen = numFrames / stepSize
val destOffW = destOffFr / stepSize
val startSrcW = startSrcFr / stepSize
val lastOffW = (startSrcW + srcNumM + destOffW).min(inLen)
val dstLen = inLen - lastOffW
val dstNumM = (dstLen - sideLen).max(0)
val dstNum = dstNumM + 1
val numRuns = srcNum * dstNum
srcNum .poll("srcNum")
dstNum .poll("dstNum")
covSize.poll("covSize")
numRuns.poll("numRuns")
def mkMatrix(in: GE): GE = {
val lap = Sliding(in, fftSize, stepSize) * GenWindow.Hann(fftSize)
val fft = Real1FFT(lap, fftSize, mode = 2)
val mag = fft.complex.mag
val mel = MelFilter(mag, fftSize/2, bands = numMel,
minFreq = minFreq, maxFreq = maxFreq, sampleRate = SR)
val mfcc = DCT_II(mel.log.max(-320.0), numMel, numCoef, zero = 0 /* 1 */)
mfcc
}
def mkSpanSigSrc(): GE = {
val in0 = mkIn()
val in1 = in0.drop(startSrcW * stepSize)
val in = in1.take(srcLen * stepSize)
val mfcc = mkMatrix(in).take(numCoef * srcNum)
val slid = Sliding(mfcc, covSize, numCoef)
val rp = RepeatWindow(slid, size = covSize, num = dstNum)
rp
}
def mkSpanSigDst(): GE = {
val in0 = mkIn()
val dropFr = (startSrcW + destOffW) * stepSize
val in1 = in0.drop(dropFr)
val in = in1.take((dstNum + srcNumM) * stepSize)
val mfcc = mkMatrix(in).take(numCoef * (dstNum + srcNumM))
val slid = Sliding(mfcc, covSize, numCoef)
val spanStart = ArithmSeq(0, covSize, srcNum)
val spanStop = spanStart + dstNum * covSize
val spans = spanStart zip spanStop
val slic = Slices(slid, spans)
slic
}
val mfccTotalSize = covSize * numRuns
val sigSrc = mkSpanSigSrc().take(mfccTotalSize)
val sigDst = mkSpanSigDst().take(mfccTotalSize)
val covIn = Pearson(sigSrc, sigDst, covSize)
val keys = covIn
Length(sigSrc).poll("sigSrc.length")
Length(sigDst).poll("sigDst.length")
Length(keys) .poll("keys.length")
val keysEl = keys.elastic()
val values = Frames(keysEl) - 1
// highest covariances mapped to frames
val top = PriorityQueue(keysEl, values, size = 1)
val srcIdx = top / dstNum
val dstIdx0 = top % dstNum
val dstIdx = dstIdx0 + srcIdx // 'pyramid'
val topSrcFr = (startSrcW + srcIdx) * stepSize
val topDstFr = (startSrcW + destOffW + dstIdx) * stepSize
top .poll("top")
srcIdx.poll("srcIdx")
dstIdx.poll("dstIdx")
MkLong("res-src", topSrcFr)
MkLong("res-dst", topDstFr)
{group: fsc3, kind: code}
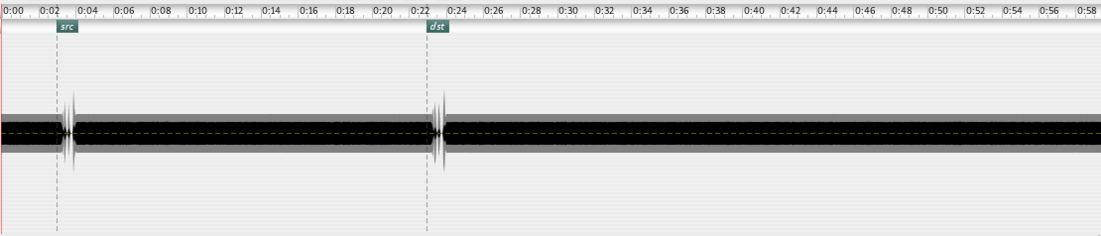
Test sound signal embedding within white noise an articulated gesture of one second. Validation: markers indicate "correct" search results.
{kind: caption, group: fsc4, keywords: [search]}
{date: 201208}
So now I have a working algorithm for performing the “step around”. I always noted the feature of audio files as the input and output of processes being their generic connectability or operational closure to use the Varela/Luhmann'ish term. The audio file does not reveal any semantic or structural information by itself; the algorithm that processes an audio file in many cases does not care whether that file contains a fragment of speech, a field recording, a synthesised sound, etc.
But there is also a downside to the “flattening operation” of bouncing. At this stage, I am not decided whether Shouldhalde will be a “stereo album”, or multi-channel electroacoustic concert pieces, or “material” for a variety of forms (something I am trying to pursue as a project on its own, moulding it into hybrid forms between electroacoustic music, improvisation, and installation). In any case, the spaciousness of the timeline structure of Shouldhalde would disappear if I mixed all signals together to a stereo file for processing in “step around”.
{persons: [Niklas Luhmann, Francisco Varela], artwork: Shouldhalde, keywords: [_, file, connection, hybrid, timeline], group: fsc5}
SoundProcesses control program code for ping-pong iterating the left hand FScape process. Notice how this is a lot longer than the DSP code (a reason also being that it renders a user interface).
{kind: caption, group: fsc11}

{date: 201208}
Therefore, I created different buses and distributed the materials so that there are no temporal overlays within a single bus. A bit like placing things on different tracks, although I rejected the notion of fixed tracks in Mellite. Still, I used colour marking to better see which are the bus assignments. For this example, I needed four stereo buses, resulting in an eight channel bounce that could be reorganised by “step around” (the algorithm uses a mono mix to calculate the correlations).
{group: fsc5, keywords: [_, colors, correlation]}
// version 26-Nov-2020
val rMatch = Runner("run-match")
val mMatch = rMatch.messages
mMatch.changed.filter(mMatch.nonEmpty) ---> PrintLn(mMatch.mkString("\n"))
val rWriteDb = Runner("run-combine")
val rWritePh = Runner("run-combine")
val in = AudioFileIn()
in.value <--> Artifact("in")
val out = AudioFileOut()
out.value <--> Artifact("out")
out.fileType <--> "out-type".attr(0)
out.sampleFormat <--> "out-format".attr(2)
val outDb1 = AudioFileOut()
outDb1.value <--> Artifact("out-db-temp1")
outDb1.fileTypeVisible = false
outDb1.sampleFormatVisible = false
val outDb2 = AudioFileOut()
outDb2.value <--> Artifact("out-db-temp2")
outDb2.fileTypeVisible = false
outDb2.sampleFormatVisible = false
val outPh1 = AudioFileOut()
outPh1.value <--> Artifact("out-ph-temp1")
outPh1.fileTypeVisible = false
outPh1.sampleFormatVisible = false
val outPh2 = AudioFileOut()
outPh2.value <--> Artifact("out-ph-temp2")
outPh2.fileTypeVisible = false
outPh2.sampleFormatVisible = false
val ggGain = DoubleField()
ggGain.unit = "dB"
ggGain.min = -180.0
ggGain.max = +180.0
ggGain.value <--> "gain-db".attr(-0.2)
val ggGainType = ComboBox(
List("Normalized", "Immediate")
)
ggGainType.index <--> "gain-type".attr(0)
def mkLabel(text: String) = {
val l = Label(text)
l.hAlign = Align.Trailing
l
}
def left(c: Component*): Component = {
val f = FlowPanel(c: _*)
f.align = Align.Leading
f.vGap = 0
f
}
val p = GridPanel(
mkLabel("Input:" ), in,
// mkLabel("Input Start:"), left(ggUseStart, ggStart),
// mkLabel("Input Length:"), left(ggUseLength, ggLength),
mkLabel("Output:"), out,
mkLabel("Temp DB 1:"), outDb1,
mkLabel("Temp DB 2:"), outDb2,
mkLabel("Temp PH 1:"), outPh1,
mkLabel("Temp PH 2:"), outPh2,
mkLabel("Gain:"), left(ggGain, ggGainType),
)
p.columns = 2
p.hGap = 8
p.compact = true
val resMatchSrc = Var(0L)
val resMatchDst = Var(0L)
val specIn = AudioFileSpec.read(in.value()).getOrElse(AudioFileSpec.Empty())
val inFrames = specIn.numFrames
//val SR = "sample-rate".attr(44100.0)
val SR = specIn.sampleRate
val resDbLen = Var(0L)
val resPhLen = Var(0L)
val renderEnabled = Var(true)
val dbInFile = Var(in.value()) // XXX TODO no Artifact.Empty()
val dbOutFile = Var(outDb1.value()) // XXX TODO no Artifact.Empty()
val phInFile = Var(outPh2.value()) // XXX TODO no Artifact.Empty()
val phOutFile = Var(outPh1.value()) // XXX TODO no Artifact.Empty()
val iter = Var(0)
val fadeDur = 0.3
val corrDur = 1.0
val startMatchSec = 0.5
val lenMatchSrcSec = 10.0
val offsetMatchSec = 2.0
val minDbDur = startMatchSec + lenMatchSrcSec + offsetMatchSec + corrDur
val minDbDurFr = (SR * minDbDur).toLong
val fadeFr = (SR * fadeDur).toInt
val corrFr = (SR * corrDur).toInt
val corrFrH = corrFr/2
val fadeFrH = fadeFr/2
val actMatch = Act(
PrintLn("Starting match. db frames = " ++ resDbLen.toStr),
rMatch.runWith(
"in" -> dbInFile,
"start-src" -> startMatchSec,
"dur-src" -> lenMatchSrcSec,
"offset-dst" -> offsetMatchSec,
"corr-dur" -> corrDur,
"res-src" -> resMatchSrc,
"res-dst" -> resMatchDst,
)
)
val actRender = Act(
renderEnabled .set(false),
iter .set(1),
resDbLen .set(inFrames),
resPhLen .set(0L),
dbInFile .set(in.value()),
dbOutFile .set(outDb1.value()),
phInFile .set(in.value()), // outPh2.value()), // unused in first iteration
phOutFile .set(outPh1.value()),
actMatch,
)
val actRenderNext = Act(
If (resDbLen >= minDbDurFr) Then {
Act(
iter.set(iter + 1),
PrintLn("Next iteration " ++ iter.toStr),
If ((iter % 2) sig_== 0) Then {
Act(
dbInFile .set(outDb1.value()),
dbOutFile .set(outDb2.value()),
phInFile .set(outPh1.value()),
phOutFile .set(outPh2.value()),
)
} Else {
Act(
dbInFile .set(outDb2.value()),
dbOutFile .set(outDb1.value()),
phInFile .set(outPh2.value()),
phOutFile .set(outPh1.value()),
)
},
actMatch,
)
} Else {
Act(
PrintLn("DB exhausted."),
renderEnabled.set(true),
)
}
)
val startPhA = 0L
val stopPhA = resMatchSrc + corrFrH + fadeFrH
val startPhB = resMatchDst + corrFrH - fadeFrH
//val offPhB = stopPhA - fadeFr
val stopPhB = startPhB + fadeFr
val startDbA = stopPhB
val stopDbA = Long.MaxValue
val startDbB = stopPhA - fadeFr
//val offDbB = ...
val stopDbB = startPhB
rMatch.done ---> Act(
PrintLn("Match done: src = " ++
resMatchSrc.toStr ++ ", dst = " ++ resMatchDst.toStr),
rWriteDb.runWith(
"in-a" -> dbInFile,
"in-b" -> dbInFile,
"start-a" -> startDbA,
"stop-a" -> stopDbA,
"start-b" -> startDbB,
"stop-b" -> stopDbB,
// "offset-b" -> offDbB,
"prepend" -> false,
"in-pre" -> phInFile, // unused, but must be given
"cross-fade" -> fadeDur,
"out" -> dbOutFile,
// "out-type" -> outDb.fileType(),
// "out-format" -> outDb.sampleFormat(),
"out-len" -> resDbLen,
// "gain-db" -> ggGain.value(),
// "gain-type" -> ggGainType.index(),
),
)
rWriteDb.done ---> Act(
PrintLn("DB updated. len = " ++ resDbLen.toStr),
PrintLn("startPhA 0, stopPhA " ++ stopPhA.toStr ++
", startPhB " ++ startPhB.toStr ++ ", stopPhB " ++ stopPhB.toStr),
rWritePh.runWith(
"in-a" -> dbInFile,
"in-b" -> dbInFile,
"start-a" -> startPhA,
"stop-a" -> stopPhA,
"start-b" -> startPhB,
"stop-b" -> stopPhB,
// "offset-b" -> offPhB,
"prepend" -> (iter > 1),
"in-pre" -> phInFile, // unused, but must be given
"cross-fade" -> fadeDur,
"out" -> phOutFile,
// "out-type" -> out.fileType(),
// "out-format" -> out.sampleFormat(),
"out-len" -> resPhLen,
// "gain-db" -> ggGain.value(),
// "gain-type" -> ggGainType.index(),
),
)
rWritePh.done ---> Act(
PrintLn("Output written. len = " ++ resPhLen.toStr),
actRenderNext,
)
rMatch.failed ---> Act(
PrintLn("Match failed:\n" ++ rMatch.messages.mkString("\n")),
renderEnabled.set(true),
)
rWriteDb.failed ---> Act(
PrintLn("Write DB failed:\n" ++ rWriteDb.messages.mkString("\n")),
renderEnabled.set(true),
)
rWritePh.failed ---> Act(
PrintLn("Write output failed:\n" ++ rWritePh.messages.mkString("\n")),
renderEnabled.set(true),
)
val actStop = Act(
rMatch .stop,
rWriteDb.stop,
rWritePh.stop,
renderEnabled.set(true),
)
val ggRender = Button(" Render ")
val ggCancel = Button(" X ")
ggCancel.tooltip = "Cancel Rendering"
val pb = ProgressBar()
ggRender.clicked ---> actRender
ggCancel.clicked ---> actStop
ggRender.enabled = renderEnabled
ggCancel.enabled = !renderEnabled
pb.value = (rMatch.progress * 100).toInt
val bot = BorderPanel(
center = pb,
east = {
val f = FlowPanel(ggCancel, ggRender)
f.vGap = 0
f
}
)
bot.vGap = 0
val bp = BorderPanel(
north = p,
south = bot
)
bp.vGap = 8
bp.border = Border.Empty(8, 8, 0, 4)
bp
{group: fsc11, kind: code}
{date: 201208}
Now to put back individual regions, I want to segment the output from “step around” based on silences. This is more or less easy to describe as an informal algorithm:
Algorithm:
- to section a file into regions of
signal versus silence
- there are low and high levels,
based on magnitude of sample values
- there are minimum durations of low
and high periods; i.e. in the output
there shall not be any silent period
shorter than a given duration, and
no active region shorter than another
given duration. This is achieved by
"absorbing" low regions, e.g. if the
minimum duration for low sections is
100 ms, and in the analysis there is
a low section of 50 ms, that section
is absorbed into the surrounding high
section.
- high sections trump low sections, i.e.
we do not absorb high regions within
low regions (we do not "omit" signals).
If a high section is shorter than the
minimum high duration, it is extended
to the minimum high duration; the onset
stays the same, but the region's end is
moved forward in time. For example if
a high region starts at 4.0s and lasts
for 0.1s, and minimum high duration is
0.5s, than the region begins at 4.0s
and ends at 4.5s (instead of 4.1s).
Making that operable in imperative code would be simple. But in terms of signal flow in FScape, that is quite difficult without knowing ways and tricks to formalise these steps and constraints.
{group: fsc5, kind: pseudocode, keywords: [silence, segmentation, duration, constraints]}
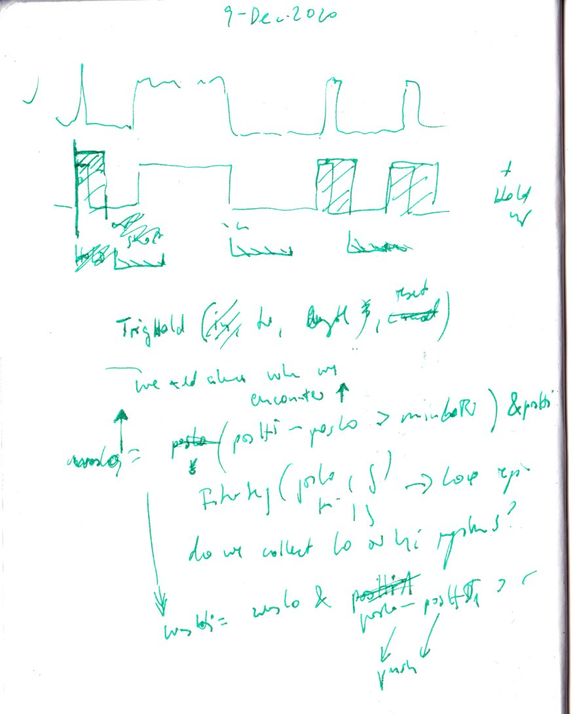
{date: 201210}
Like so often, a simple UGen was missing that would make this anything but a convoluted translation. I sketched out on paper that a block would be useful that keeps a gate or trigger signal “high” for a period of time. I call this new UGen TrigHold, even though I have moved away from “trigger” signals altogether in favour of “gate” signals; they can be used to trigger something at sample level precision, whereas a trigger can only occur every two sample frames.
{keywords: [_, UGen, translation, trigger]}
Visually verifying the output of the silent/non-silent partitioning.
{kind: caption, date: 201210, group: fsc8}
The algorithm could be implemented by introducing a new UGen TrigHold.
{kind: caption, date: 201210, group: fsc7, keywords: [UGen]}

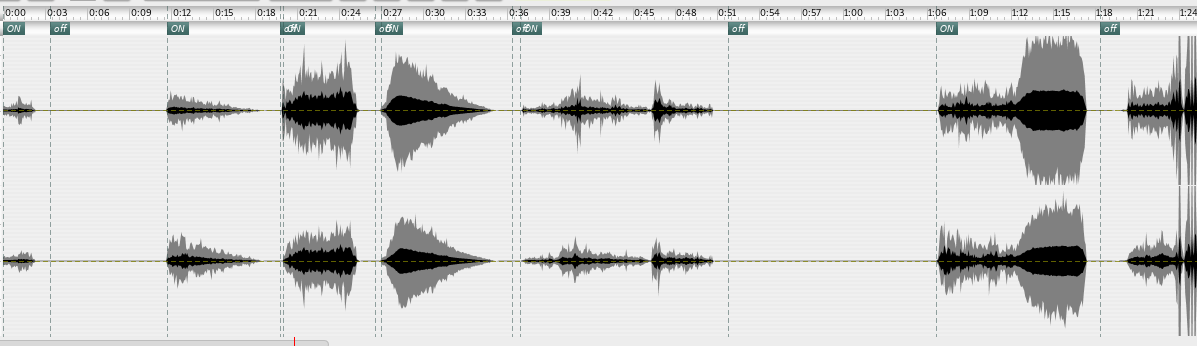
Timeline view after running the silent/non-silent segmentation on the reconstructed four layers of output from “Step Around”. A glue program in SoundProcesses' Control abstraction runs the FScape analysis, and pastes the different audio chunks, coloured red in the bottom section of the screenshot, back onto the timeline. I have already started editing the results, as the light gray tinted boxes (muted) indicate. When I work in the nights, I tend to use the dark skin for Mellite, where the background is dark gray, and the sonogram overviews of the audio regions are of a bright-on-dark palette.
{kind: caption, date: 201210, group: fsc9, keywords: [timeline, segmentation, silence, colors]}
Implementation of the silent/non-silent segmentation in FScape. The resulting position list is returned, as well as a new “condensed” audio file produced. MkIntVector collects the positions and segment lengths that are returned to the calling program.
{kind: caption, date: 201210, group: fsc10, keywords: [segmentation, UGen]}
// version 09-Dec-2020
def mkIn() = AudioFileIn("in")
val in = mkIn()
val numFrames = in.numFrames
val SR = in.sampleRate
val inM = Mix.MonoEqP(in)
val minDur = "min-dur".attr(1.0)
val padDur = "pad-dur".attr(0.1)
val thresh = "thresh-db".attr(-144.0).dbAmp
val minFr = (minDur * SR).toInt.max(1)
val padFr = (padDur * SR).toInt.max(0)
val padFrH = padFr >> 1
val minFrM = minFr - 1
val fileType = "out-type" .attr(0)
val smpFmt = "out-format" .attr(2)
val gainType = "gain-type" .attr(1)
val gainDb = "gain-db" .attr(0.0)
val inAna = inM.abs ++ DC(0.0).take(minFr) // pad so we always fall back 'down'
val above0 = inAna > thresh
val above = TrigHold(above0, minFr /* minHiFr */)
val slope = Differentiate(above)
val on = slope > 0
val off = slope < 0
val pos = Indices(slope)
val posOn = FilterSeq(pos, on )
val posOff = FilterSeq(pos, off) - minFrM
//posOn .poll(1, "on ")
//posOff.poll(1, "off")
val spans = posOn zip posOff
val spanLens = posOff - posOn
val slices = Slices(mkIn(), spans)
val padded = ResizeWindow(slices, spanLens, stop = padFr)
val sig0 = padded
val gainAmt = gainDb.dbAmp
def applyGain(x: GE) =
If (gainType sig_== 0) Then {
val rsmpBuf = BufferDisk(x)
val rMax = RunningMax(Reduce.max(x.abs))
// mkProgress(rMax, "analyze")
val maxAmp = rMax.last
val div = maxAmp + (maxAmp sig_== 0.0)
val gainAmtN = gainAmt / div
rsmpBuf * gainAmtN
} Else {
x * gainAmt
}
val sig = applyGain(sig0)
val written = AudioFileOut("out", sig,
fileType = fileType, sampleFormat = smpFmt, sampleRate = SR)
//RunningSum(spanLens + padFr).poll(1, "stop"
MkIntVector("res-in-pos", posOn)
val spansOut: GE = {
val acc = RunningSum(spanLens + padFr)
val start = 0 +: acc
val stop = acc - padFrH
start zip stop
}
MkIntVector("res-out-span", spansOut)
{group: fsc10, kind: code}