FIXED MEDIA and the METAMORPHOSIS of the PERFORMATIVE RESONANCE
In a traditional context of musical performance practice, most musicians perform works by composers using a pre-conceived instrument; the distinction between composer, performer and luthier is most of the time very clear. In fact, we could argue that it takes a necessarily different set of skills to effectively accomplish each of these functions. However, in the current landscape of audio-visual improvisation/performance practice, to which this work belongs, these roles are most of the times interwoven or even superimposed. In a sense, artists also need to be the inventors and engineers of their own instruments in order to perform. Currently, propelled by advancements in technology, the lowering of its cost and its increasing ease of use, artists are able build their own software using programming environments such as Max, Touch Designer, VVVV, Processing or SuperCollider to explore and materialize their concepts. In this type of environment, they can realize their full creative potential by building custom solutions for each artistic project, if needed, and tailor them to very specific goals.
This section aims to describe the technical specifications, procedures and related custom programming of the audio-visual installation, which granted us the possibility of materializing our theoretical concepts and action plans.
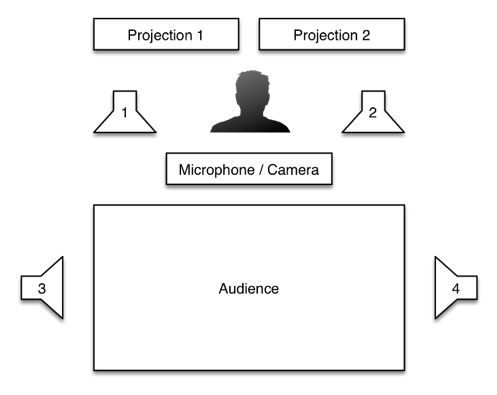
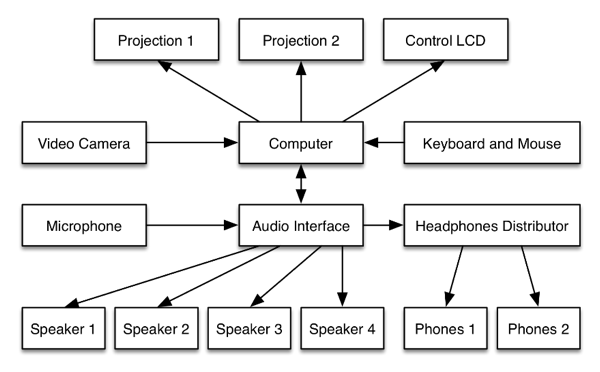
The proposed system had the function to record, process and manage the playback of video and audio content, in a feedback chain with the performer.
The nearest pair of speakers to the performer were responsible for playing a previously structured sequence that served as the base content. In contrast, the lateral pair of speakers were filled up with recorded excerpts of the performance, played in a semi-random manner, with an increasing rate of temporal discontinuity and overlapping sound elements throughout the installation period. This principle was also applied to the visual part of the system, making the result progressively grow in density and complexity. For this installation to not disturb the regular activity of the facility, 2 pairs of headphones were also included, that allowed the audience to experience it at any time. To this end, a separate audio mix containing the contents of all speakers was purposely built.
The audio base content, fixed media, referred above, was produced using a DAW[1], deconstructing parts of the text and more specifically the sentence “Espelho meu, espelho meu, que espelhas tu que não eu?”[2] with a differentiated articulation of the phrase and its syllables[3].
Concerning the video, we worked on several videos that were pre-recorded and shot with the concept of transformed mirror. In that regard, we captured images that usually do not hold our attention on our daily life with a particular attention to the lights as they have a great importance in the way they transform the way we see what surround us.
The live performances and the performance’s rehearsals were also recorded in a perspective of including the experimentation process, the pre-performance process that already contains the final performance in potency.
The video programming took advantage of the OpenGL graphics API whenever possible, using the GPU to accelerate most procedures, instead of relying on the main CPU. This approach gives us good graphics performance (multiple screens, high resolutions and high frame rates) as well as the added advantage of freeing up the CPU for the processing of audio tasks, thus increasing the overall stability. This is undoubtedly a key requirement for a system such as this, since it’s intended for it to be continuously active for days on end.
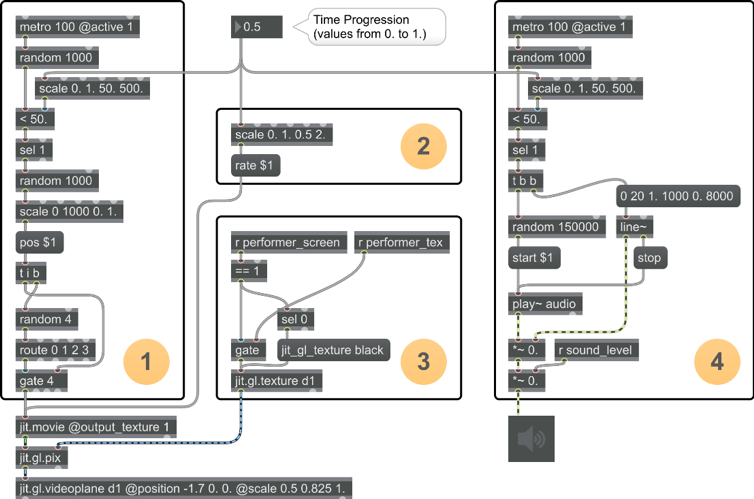
The programming of this audio-visual system was accomplished with the Max visual programming language. A small set of audio and video assets was previously prepared to serve as the basis for the performance. The application we developed received the captured audio and video contents of each performance and saved the resulting files to a folder that was being constantly scanned for new content. This way, the files of each recorded performance became available as material that could be used at a later time, in a processed and non-linear manner.

[1] DAW - Digital Audio Workstation. In this case we used the software Reaper to build the fixed media. The multitrack edition enabled us to create the different layers of deconstruction of the text. All the audio content is created using the performer’s voice.
[2] Mirror, mirror, who do you mirror that not me?
[3] Some of the possibilities that were used in the process of deconstructing the text: Espelhastuque, Espelhastuquenão, tuquenão, espequenão, espequeu, espelheu, tuqueu, quetuque, quetuquenão, quespetuque, lhasquenão, lhaseu, queu, queque, quequenão, tueu, lhastu, [...]

