
On Accumulation of Hesitation: Timbre Networks and mapping as a compositional strategy
Introduction
This case study presents the search for a creative procedure that would encompass the multithreaded role of the computer music practitioner, demonstrating how certain aspects of instrument design in electronic music can inform the organisation of musical structures and, in turn, the performance practice of the instrument itself.











1 “Man hoffte (und forderte programmatisch) ein lückenloses Kontinuum aller Klangfarben; nicht nur aller Klangfarben, sondern das Kontinuum zwischen der in sich stationären Farbe und der musikalischen Struktur. Als Ziel zeigte sich die in Konturen gesetzte, die bewegte Farbe”. (Some specificity might have been lost in my English translation.)
Context
Timbre Networks: a definition
We can define a network for the present purpose as a system of asymmetric relations between discrete objects that allows an exchange of information between connected objects. Following the notion of connectionism in network theory, better known as neural networks, we can say that a model for such a network is “loosely defined around three aspects: computing nodes, communication links, and message types.” (Judd 1990: 2) We could then describe Timbre Networks as a model for organising the threads connecting the different musical elements that play a role in live electronic music. In using this term I aim for a systematic organisation of the possible relationships between computer, musical instrument(s) and performer(s).
By focusing specifically on timbre and using it as the foundation of these relationships, I aspire to create a system in which the sound sources, on one hand, and their manipulation through performance, on the other, become part of a single entity, in a more concrete sense than would be provided by a mere conceptual definition. In other words, I seek to define a compositional strategy based on systematising the relationship between a determined number of sound elements and their potential interdependence, leaving in the performer’s hands the responsibility for unfolding the musical structure over time.
The structure of a particular Timbre Network can be characterised as a complex of musical actors (both human and non-human), their interdependent relationships, and the behavioural developments that can be induced through performance. As a compositional procedure, a Timbre Network has to define:
- The nodes (actors) of the network.
- The threads (relationships) between them.
- How those nodes and threads are malleable over time, either
through real-time manipulation by a performer or through using predefined interdependent variables.
Once these initial states are defined, additional compositional procedures to develop the time structure of the musical piece may and should be used. The question then arises of whether it would be possible to derive the musical time structure from the timbre network structure itself.
Timbre Networks provides a compositional method for generating outside-time structures by focussing on the composition of predefined initial states of a musical system that can (and should) evolve in time through performance. The concept of outside-time structures was introduced by Iannis Xenakis, who made a distinction between structures such as scales or modes (outside-time) and the melodies constructed from them (in-time). Xenakis (Xenakis 1992: 207) points out that
It is necessary to divide musical construction into two parts [...]: l. that which pertains to time, a mapping of entities or structures onto the ordered structure of time; and 2. that which is independent of temporal becomingness. There are, therefore, two categories: in-time and outside-time.
Included in the category outside-time are the durations and constructions (relations and operations) that refer to elements (points, distances, functions) that belong to and that can be expressed on the time axis. The temporal is then reserved to the instantaneous creation.
The results of using Timbre Networks can be understood as hybrid musical entities with characteristics of both an instrument and a composition. Timbre Networks may be seen as a way of applying compositional thoughts to mapping procedures.
The idea of creating a system that generates both the sound and the time structure of a composition has been explored by composers other than myself, most notably by Gottfried Michael Koenig, who had “hoped for (and postulated programmatically) a seamless continuum of timbres; not only between all timbres, but between internally static sound-colour and musical structure. The goal revealed itself to be the colour set in contours, the fluctuating sound-colour.”1 (Koenig 1992: 78)
This vision was successfully realised in his work Terminus (1962). On this composition, musicologist Elena Ungeheuer (Ungeheuer 1994: 32) states that
a complex sound metamorphosis results from the superimposing of semi-automatic modulation processes, which are not object to further manipulations once the machine has started. The composer does not control the sound elements themselves, but the steps of sound-forming. The musical form – describing a path through the steps of sound modulation – guarantees that structures can be recognised and distinguished.
My departure from defining a “final” path through the steps, and, in consequence, fixing a final version of a piece, led me to the separation of the in-time structure of a composition from the outside-time structure of the timbre network. I did this to emphasise the importance of the performer actively contributing to the unfolding of a musical structure, leaving him or her with the responsibility for its manipulation and development. This is made possible by considering and implementing a compositional strategy which defines the identity of a piece of music principally in terms of initial states.
I would argue that for a musical system (the Timbre Network and its sound-interdependent variations) to comprise an interesting set of relationships, its development need not necessarily be governed by an intrinsic time-structure. Nevertheless, music is clearly a phenomenon which unfolds over time, which means that the timbre-network itself must be augmented by a set of in-time relationships contributed by the performer.
Composing the network
The elements of a network may be divided into nodes and threads. In the present case, the nodes are the instruments, which are responsive to the physical control of a human performer. These may be either traditional instruments or electronic sound sources (such as a computer or a part of the computer system). I describe threads here as the predefined interdependent connections between each instrument. They might be seen as the constraints of the system, but also as its intrinsic characteristics. What is important to acknowledge is that the sound transformations of the instruments are potentially considered both as nodes and as threads. This is to say that the nature and extent of the sound transformation can either change the inner characteristics of a source (creating a new node) or extend the natural character of an instrument (thus generating another thread between two nodes).
I consider timbre to be a multidimensional music parameter. To allow the potential timbre complexity of an individual sound source to merge and interact with others in a Timbre Network, it is important as a first step in the composition of the network to define the behavioural limits of the sound sources (the initial nodes of our network) and, later, to focus on the inner complexities of these nodes and on how they can be connected within the complex of the network as either:
- Control information passing between two or more sound sources
(a thread between nodes)
- Intrinsic richness of the node itself (which will still be subject to variations through performance)
A Timbre Network allows a number of computer systems to act in harmony with one another in a range of alternative configurations. Computers can be used as independent sound sources, with or without the ability to be influenced by a performer; thus, a computer system can be seen as both a static and an active node in the network. Computers can also serve as dedicated signal processors for other nodes, or as signal-to-control translators, working as threads between elements of the network. If more than one computer is used within a structure, one of them must assume the role of the core of the network. The core of a Timbre Network is the place where node characteristics are extracted and transformed into threads (control parameters) for other nodes, and where the initial settings of node/thread relationships can be stored, recalled and modified.
Project
An example of an actual implementation of the Timbre Network concept is Accumulation of Hesitation (AoH), a piece that I started to compose as a “Timbre Network in a box”. In this setup, all nodes and threads are generated in a single system implemented in the Max/MSP environment and manipulated by a single performer. A later expansion to AoH is a no-input mixer, which serves as an extra source for the network, as both sound generator and control generator.
Architecture of the system
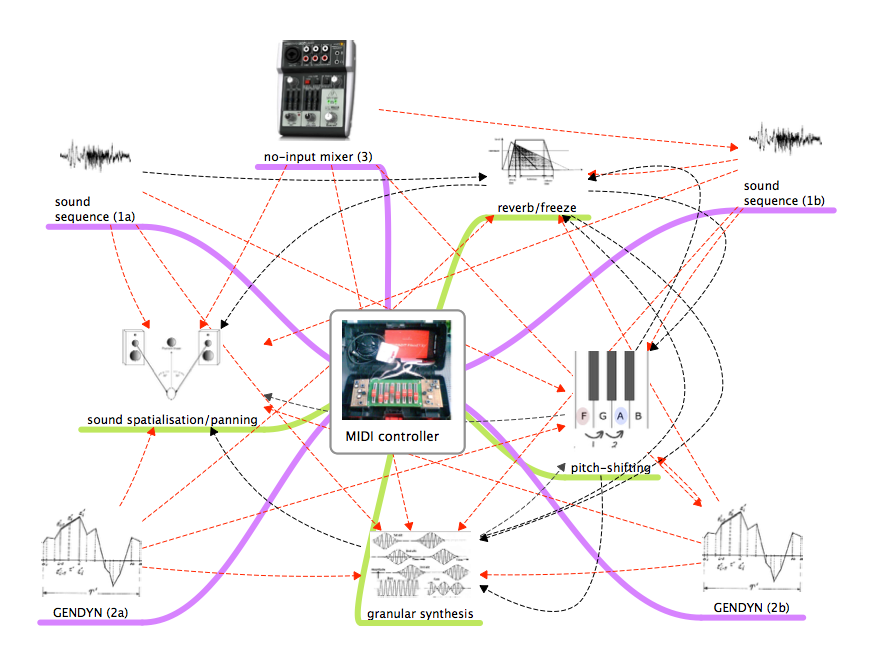
AoH consists of five basic sound sources (nodes) and four engines of sound manipulation (threads). Additionally, the output of each sound source or node is translated within the network into control information to trigger global changes in the calibration of the sound manipulation engines (threads). The pacing of these changes within the predefined boundaries of each calibration state is carried out by the performer.
The pre-composed sequences are two-minutes long and based on similar analogue patches to the ones used in my 2005 composition Lonquimay.89.3
In that piece, fixed timbres were created to be further articulated by a series of behavioural control patches generated in the ACToolbox environment created by Sonology faculty member Paul Berg.4
The sequences used in AoH comprise four superimposed layers of sounds: tone changing to pulse, pulse to tone, static tones to silence and static pulses to silence, each with an independent rate.
2 A note on GENDYN: created by Xenakis, the dynamic stochastic synthesis consists of waveforms that can vary continuously according to a pre-formalised stochastic function. “Instead of ‘curving’ the waveform, Xenakis interpolated the breakpoints (samples) in a linear way. The horizontal and vertical proceeding of the points in the successive cycles are calculated on the basis of a probability formula, causing a kind of stochastic amplitude modulation (vertically) and frequency modulation (horizontally). To control the timbres, Xenakis must determine the range of the variation of points of a cycle, so that the more radical the variation, the noisier the timbre, and vice versa.” (Penov 2006: 2)
3 More information on Lonquimay.89, including media samples is available at http://juanparrac.bandcamp.com/track/lonquimay-89.
4 For more information on the ACToolbox, see http://kc.koncon.nl/downloads/ACToolbox/.
5 The original work by Pabon on the porting of GENDYN onto the Max/MSP environment has been continued and further documented by Johan van Kreij.
For more information, visit http://www.jvkr.nl/home/files/gendy-non-standard.html
Sound sources: Nodes
Two of the five sound sources in the AoH piece are pre-composed sound-sequences (labelled 1a and 1b) realised at the BEA5 analogue studio of the Institute of Sonology in The Hague, two are instances of “GENDYN” (a synthesis algorithm developed by Iannis Xenakis)2, and one is a small analogue mixer modified to generate pulses and clean, almost sinusoidal tones.
The next two sound sources (labelled 2a and 2b) are produced by “gendy~,” an abstraction of the dynamic stochastic synthesis algorithm developed by Iannis Xenakis and ported into the Max/MSP environment by Sonology faculty member Peter Pabon at the Institute of Sonology of the Royal Conservatoire of The Hague.5
The fifth sound source in AoH is a small analogue mixer, the audio outputs of which are connected to its inputs. This permits the generation of simple pulses and quasi-sinusoidal tones from internal feedback. Although audible throughout the piece, the main purpose of this last sound source is to provide continuous control-information threads for the manipulation engines affecting the other two sources.

Additionally, every node has its own set of parameters that are already defined and stored in presets. In the case of the pre-recorded sequences, these parameters are playback speed, playback direction and loop points. For the gendy~ engines, the parameters are:
- Frequency
- Distribution warping
- Jitter mask for period-to-period fundamental frequency variation
- Size of the random number tendency mask for Y-axis variation
- Number of break point samples in the buffer for Y-axis variation
- Time-warping factor
- Size of the random number tendency mask for time axis variation
- Number of break point samples in the buffer for time axis variation
Sound manipulation engines: Threads
Each of the sound sources communicates with the others through a sound manipulation engine, which affects its sonic properties directly and provides control information for the sound manipulation of each of the other sources. An exception to this connection is the external analogue mixer, which only provides control information to the other sources and does not receive control information from anyone other than the performer. The engines of sound manipulation are:
- Sound spatialisation
- Reverb/freezing
- Pitch shifting
- Granular synthesis
The changes from one preset to another for every node are triggered during performance in two ways: (1) when any of the sound manipulation engines crosses a predetermined threshold value, or (2) when signals produced by the analogue mixer induce a sudden shift in those values.
6 Developed as an electronic music concept by Gottfried Michael Koenig, and implemented in algorithmic composition by Paul Berg, a tendency mask is a set of dynamic boundary points between which elements will be selected at random or according to various other kinds of statistical distribution.
Connecting the network
Each sound source in AoH is connected to two different sound manipulation engines, but only one of the connections is made audible. The non-audible result is transformed into control information, which continuously modifies one parameter of the three remaining engines. For example, sequence 1a is sent through both granular synthesis and pitch shifting. While the granulated output is audible, the pitch-shifted sequence is converted into a numeric value to control:
- Reverb size value (audibly affecting gendy~ 2).
- Sound spatialisation, randomly chosen from a list of start and end points and time durations of the spatial trajectory (audible in sequence 2b).
- A tendency mask6 for grain density (audible on sequence 1a itself).
The unfolding of the piece, rather than being based on a linear time structure, proposes an evolutionary approach, based on the performer’s manipulation of predefined initial settings stored for each of the sound sources. This means that, rather than following a predetermined sequence of events, the structure of the piece becomes manifest only through the decisions of the performer, who chooses when and how these elements appear, interact and transform one another. The decision to approach time-structure in this way, rather than in a more traditional timeline fashion, can be justified under the following headings:
- The character of the sound sources: The common denominator between the compositional method behind the pre-recorded sequences, Xenakis’s GENDYN and the nature of the no-input mixer sounds is that they are all sources with a rich inner complexity, yet which exhibit rather static behaviour on the macro-level, so that any real-time manipulation is strongly perceptible as a musical contribution by the performer.
- The character of a network: For similar systems, but where more than one performer is involved, a preconceived time structure might be preferred. The intrinsic nature of a timbre network is rather static; that is, it is not as concerned with time evolution as it is with material interconnectivity.
- The character of a performer: This approach emphasises the importance of the performer as a contributor not only of musical expression but also of musical structure.
On a performance level, the goals of a timbre network as a structure are:
- To define the initial sonic limitations and their interconnecting expressive constraints.
- To preserve the identity of the original network during a performance.
- To leave the performer(s) responsible for expanding, pacing and controlling the dynamics of the musical result.
Performance control
AoH is intended to have a performance-driven compositional structure; therefore, in addition to the internal changes of the system due to the network connections, a performer is required to control the pacing of the overall result and to refine the variations in every sound transformation parameter. Additionally, the performer has complete control over the main parameters of a granular synthesis engine (grain pitch, size and density) which are mapped to an external hardware controller.
Reflection
Accumulation of Hesitation demonstrated how the concept of Timbre Networks, based on mapping procedures, can be used to create an environment that shifts between an instrument and an articulated piece. The articulator in this case is the performer, who is responsible for unfolding over time the inner structure of the piece, connecting through the act of performance Xenakis’s notions of outside-time and in-time in music structure. How to articulate these ideas in relation to traditional instruments will be one of the motivations behind PLP I and KVSwalk.
References
Judd, J. Stephen (1990). Neural Network Design and the Complexity of Learning. Cambridge, MA: MIT Press.
Koenig, Gottfried Michael (1992). “Bilthoven Lectures 1962/63.” In Roger Pfau, Wolf Frobenius, Stefan Fricke and Sigrid Konrad (eds.), Ästhetische Praxis: Texte zur Musik (vol. 2, pp. 56–125). Saarbrücken: Pfau.
Penov, Ivan (2006). “Iannis Xenakis: ‘S.709”. Retrieved 4 November 2014, from https://sites.google.com/site/ivanpenov/xenakis%27s.709.
Ungeheuer, Elena (1994). “From the Elements to the Continuum: Timbre Composition in Early Electronic Music.” Contemporary Music Review 10/2: 25–33.
Xenakis, Iannis (1992). Formalized Music: Thought and Mathematics in Composition. Revised edition. Stuyvesant, NY: Pendragon Press.