IN SYNC WITH A MACHINE

1. PROMPTING AS CO-CREATION: EXPLORING THE AESTHETIC POTENTIAL OF HUMAN-AI COLLABORATION
The aesthetic potential of human-AI co-creativity is emerging as a powerful area of exploration, particularly in the context of prompting as a dialogical process for artistic research. At the intersection of human agency and machine intelligence, prompting is more than a technical tool; it is a creative catalyst that opens up new avenues for collaboration and expression between humans and large language models (Balaska 2022; White et al. 2023). This paper examines the role of prompting in fostering co-creative interactions and explores how this process transcends simple command-based exchanges to become a profound, immersive experience that combines storytelling, interaction design, and aesthetic practice. It draws parallels to concepts of New Media Dramaturgy (NMD), which has the ability to generate lived emotional experiences through performed media by actively engaging visitors in the reception of art. This approach fosters a sense of possibility and unfolding events, extending beyond the artwork itself into the audience’s experience, ultimately involving them in the creative process (Eckersall et al. 2017; 2014). In order to achieve the goal of examining the artistic use of prompting, an interdisciplinary team of artists with backgrounds in Cognitive Science, Computer Science, Media Art, Performing Arts, and Scenography came together to explore and create an interactive piece of media art, pushing the boundaries of artistic human-AI collaboration. In its artistic context, prompting has roots in theater, where a prompt acts as a suggestion that inspires performers, providing a starting point for spontaneous creative expression in improvisational theater, or refers to the discreet assistance given to actors during a performance when they forget their lines. However, when applied to human-AI interaction, prompting evolves into a more nuanced and open-ended exchange. Unlike prompt engineering, which is focused on aligning AI behavior with specific human goals through direct commands or instructions, prompting in a co-creative context emphasizes inspiration and interpretation (White et al. 2023). It serves not as a rigid directive but as an invitation to the machine to generate creative outputs that are not fully predetermined by the user (Mikalauskas et al. 2018). In our installative context of the AI-based storytelling machine ANA, this shift from instruction to inspiration opens up significant aesthetic possibilities. Here, the elaborated prompt design of ANA is shaping prompts that encourage an AI to interpret, respond, and co-create alongside a human partner, bringing forth a new dynamic of interaction—one that blurs the boundaries between a human author and a machine. Prompts are less about dictating a precise outcome and more about establishing a dialogical space where human intent and machine interpretation meet in unexpected, emergent ways. The use of multimodal prompts, incorporating not only text but also visual and auditory cues, extends the potential for human-AI collaboration (Radford et al. 2021). This paper will explore how co-creative prompting in an elaborated prompt design setting of the AI-based installation ANA fosters unique, immersive experiences that challenge traditional notions of authorship, creativity, and agency. Through a close examination of prompting as a creative tool and its artistic potential, we will investigate how the concept of being in sync with a machine—not just technically, but emotionally and artistically—reshapes the human-AI relationship. The artistic research question is: How does continuous real-time affective synchronization between user and machine—through emotion recognition and mood feedback—influence co-creative storytelling dynamics?

2. ANA: AN AFFECTIVE STORYTELLING MACHINE
The context in which our inquiry happened is the interactive installation ANA, which was developed by our team[1] between 2021 and 2023. The following section will provide a brief explanation of the experience, and how it is implemented, to set the stage for subsequent discussions.
ANA is a walk-in installation in the form of a photo booth that offers a ~10min interactive experience. Upon entering the booth and sitting down, there is a short, scripted introduction in which the system introduces itself and the user gets acquainted with the interaction dynamics of the experience. After that, the system starts to improvise a fictional story based on three topics the user suggests. The user and ANA both continue the story, taking turns, with ANA holding responsibility to maintain a well-formed narrative structure and ensure a dramatically interesting development of the plot (see Section 4 for an in-depth analysis of such a story). After a number of turns, the system wraps the story up with a suitable ending. It reflects with the user about the story and its creation process during a short debrief (see Section 3 for a discussion of the implications of this metacommunication). Upon leaving the booth, the system presents a printout of the unique story that was created during the experience to the user as a gift. All interactions with ANA take place via spoken—not typed— language, and also ANA’s output is presented using text-to-speech technology. Additionally, a Pepper’s Ghost illusion is used to display the improvised story in the form of seemingly free- floating text, scrolling past the user.
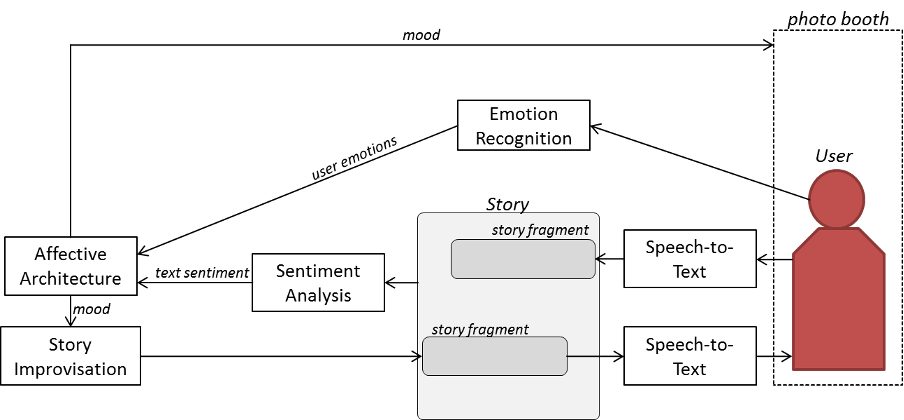
Crucially, the story and the interaction itself are influenced by the affective states of the two parties: the user and ANA.
To be able to ascribe an affect to an AI system, we implemented a computational model of affect inspired by human cognition (Gebhard 2005; as used in Berov 2023), which allows ANA to continuously simulate an ever-changing affective state. The employed affective architecture mainly consists of two parts: emotions, which in this framework are understood as valenced short-lived reactions to events; and mood, which in this framework is an aggregation of these experienced emotions into a mid-term stable state. It is this state, in the end, that affects how the affective agent acts.
We assume that human users can’t help but experience some emotions during an interaction with an affective storytelling machine. To be able to react to these emotions, ANA relies on the real-time emotion-recognition algorithm emonet (Toisoul et al. 2021) to continuously extract these users’ emotions throughout the interaction from a live video feed captured by a camera inside the booth. Emonet employs a two-part deep convolutional neural network architecture, consisting of a face-alignment part and an emotion recognition part, which uses an attention mechanism that allows the second part of the network to focus processing on the most relevant parts of a face. It was trained on the AffectNet dataset.
The emotions detected using emonet are used as input to the affective architecture outlined above, where they are processed as events. These events are appraised by the system using an interpretation of the OCC taxonomy (Ortony and Turner 1990), and in that way elicit emotions in ANA. Another input to the affective architecture is how “in sync” the system perceives the interaction to be progressing. This is determined by comparing the text sentiment of the story parts ANA contributes with the sentiment of those parts contributed by the user (we rely on GPT-4 to perform sentiment classification on both fragments, using a prompt that instructs it to assign one of three categorical sentiments to each fragment). An alignment of sentiment leads to a positive emotional appraisal, while a mismatch leads to a negative one.
These two forms of input lead to a constant stream of emotions in the affective architecture, which are aggregated, and result in a dynamic, ever-changing mood. In the employed cognitive architecture, mood is represented as a point in a three-dimensional space along the pleasure, arousal, and dominance axes. This mood, then, is used to influence the style and the content of the story parts that ANA generates, and is also expressed through the ambient lighting inside the booth (as well as floating, graph-like lines in the Pepper’s Ghost display). For instance, if the mood is high along the dominance axis, the OpenAI API is used to generate a longer text fragment than when the mood is low on dominance. Similarly, the prompt delivered to GPT-4 to create the next story fragment is adjusted to request a happy continuation if the mood is high along the pleasure axis, or sad if it is low in pleasure. Comparable considerations go into selecting the colors and intensity of the LED lights used to illuminate the inside of the booth.
Our hope is that both, story sentiment and ambiance, have an emotional effect on the user, thus establishing a bidirectional, nonverbal communication channel. A simplified schematic above summarizes how the affective architecture influences, and in turn is influenced itself, by the interaction. From a technological perspective, ANA is a fairly complex system since it combines multiple, very different modules: A remote LLM that is integrated via API calls and processes text; remote TTS and SST networks operating on text and sound, also accessed via APIs; a deep convolutional neural network, run locally and processing video data; and the affective architecture that integrates these different modalities and translates them into a dynamic state that affects the overall system’s behavior (we discuss the curiosity of such a multimodal integration further, in Section 6). It is this conglomerate that we refer to, in this paper, when we write of “the AI”. This is different from the colloquial use of the term AI, where it usually refers to an LLM and app that is used to directly prompt it. We want to emphasize that this difference is not only rooted in the additional capabilities ANA has, but also in the fact that, as opposed to e.g. ChatGPT, our users cannot prompt the systems themselves to give it commands. Their input is merely used as a part of the prompts we designed, which ensure that ANA reacts to what they say instead of fulfilling requests.
An interesting, unanticipated problem arose from the combination of different modules that comprise ANA and the time scales at which they operate. The emotions recognized by emonet turned out to be based on fleeting changes of the user’s facial features that typically occurred on the scale of a few seconds, and not too often. Thus, ANA’s emotional reactions tend to be brief, occasional bursts. At the same time, the interaction between human and machine takes place on the scale of multiple minutes, as dictated by the speed of the spoken word. The affective architecture had to come up with ways of giving individual emotions enough impact to change the mood over a long enough time, such that these changes became perceivable to ANA’s interaction partners. Detailing these solutions, like default moods and mood decay functions, lies outside of the scope of a high-level description such as the present essay. Interested readers are kindly referred to Chapter 3.3 in Berov (2023), where the architecture is discussed in detail.

The aim of the installation is to provide users with an experience in which they interact with a machine not only on a linguistic level via imperatives, as it is usually the case with LLM-based chatbots, but also on an emotional level in a multidimensional, embodied context. The user’s face provides relevant context for ANA and influences its reaction. ANA’s embodiment is expressed via the ambiance of the inside of its booth, giving the user the impression of being surrounded by its interaction partner, which underscores the non-anthropomorphic nature of its counterpart. The story generated by the two parties together provides a point of condensation and reification of the affective dynamics of the interaction, and makes these dynamics tangible for the user. The possibility of emotionally interacting, perhaps even empathizing, with a non-anthropomorphic, digital system is an uncommon experience that we hope will foster reflection about the potential of human-machine interaction.
3. METACOMMUNICATION
ANA’s objective is not only to provide a storytelling bot but rather to emphasize the relationship that emerges through human-machine interaction. A crucial aspect of this relationship is metacommunication, which refers to communication about the communication process itself. In its full scope, metacommunication involves all the cues and signals that communicating agents use to frame or contextualize their messages, such as tone of voice, body language, facial expressions, and other nonverbal elements. Metacommunication can also include explicit statements about the communication process, such as clarifications, feedback, and commentary on how a message should be interpreted.
Presently, it seems surprising that machines should be able to take part in metacommunication, but there are no technical limitations preventing them from doing so. Humans just have not seen any reason for it. ANA can be seen precisely as an attempt to design a conversational agent that transcends the limitations of manifest communication and enters into a realm of metacommunicative subtext. ANA’s setup deliberately omits most aspects of body language, primarily due to technical feasibility constraints, and instead focuses on a few specific acts of metacommunication:
- Understanding Interaction Quality: ANA attempts to gauge the quality of the interaction by reading the user’s emotional expressions and relating them to the machine’s “mood,” which is generated continuously throughout the interaction. This leads to the detection of two distinct states: being “in sync” (where human and machine share the same emotional state) and being “out of sync” (where their emotional states differ). ANA is programmed to associate “being in sync” with a high quality of interaction. This assumption seems logical, considering that the human brain might also seek moments of being “in sync” with a dialogue partner via so-called mirror neurons.
Mirror neurons are located in the motor cortex and fire when observing an action. Demonstrated via electrodes in macaques’ brains (Rizzolatti and Craighero 2004), they are also active in humans, likely embedded in a system called the parieto-frontal mirror system. They have been detected in the same brain regions as in monkeys, but not at the level of individual neurons (Van Baaren et al. 2009). The system is, in turn, only part of our systems for understanding others, but possibly the only one that enables a “first-person experience” of the experience of others (Rizzolatti and Sinigaglia 2010). Marco Iacoboni claimed to be able to detect neural mirror activity in subjects using functional magnetic resonance imaging, not only in brain regions associated with immediate motor control but also in centers for language comprehension (Iacoboni et al. 2005). These results sparked intense criticism, as MRI scanners, like those used by Iacoboni, work much too slowly to capture rapid perception processes. They may have been hastily linked to empathy. The mirror system could be better described as a simulation system that brings about the corresponding neural activation through physical imitation. Elaine Hatfield coined the term “emotional contagion” for this (Hatfield et al. 2009).
For ANA the value of being “in sync” stands for the quality of the interaction without being related to empathy in a direct way. In other words: ANA does not claim to understand or even reliably detect the emotions of the user, but only detects the “quality of the interaction” in order to be able to address it.
- Communicating Interaction Quality: ANA uses the value of being “in sync” as a basis for metacommunication. It counts the moments of synchronization with the user and provides feedback at the end of the dialogue, saying something like, “We were in sync 55% of the time. Not bad for a human and a machine!” This invites the user to reflect on the interaction quality and, in future versions, could lead to more in-depth conversations about this aspect. In our first draft ANA would just ask the user “How was it for you?”, but we dropped this direct entrance into metacommunication as it seemed too complicated for the test-users.
Introducing metacommunication into human-machine interactions clearly breaks expectations that humans have about machines: that they do not have emotions and that they do not care about the quality of the encounter. A machine that gives you feedback about the quality of being “in sync” and expresses its desire to be “in sync” with you disrupts the notion of the machine as a servant—an ever-patient, obedient butler that never communicates its inner state. ANA’s approach transforms the machine into a storytelling partner and interaction collaborator, capable of engaging in metacommunication—a domain traditionally off-limits to servants. Historically, recognizing that servants had inner lives like other human beings led to questioning master-servant relationships and to significant societal changes. There is evidence that our cultural evolution was significantly influenced by this human-servant relationship, as the scholar Juri Lotman points out in his reflections on the semiotic mechanisms of art and communication (Lotman 1981, 22–27).
- Commenting and summarizing: ANA also engages in two other forms of metacommunication by coming up with a snide summary of the story and inventing a title for the story. Through this, ANA takes the role of a commenter and even a story editor, daringly expressing a subjective perspective and framing the story, thereby framing it in a subjective way. Here, again, ANA clearly steps out of the role of a simple servant and even takes on dominant qualities.
In an artistic framework, introducing metacommunication into human-machine interaction brings to the surface underlying concepts. ANA destabilizes the presumption of the machine being “just a tool” or “something like a servant” and instead establishes it as a partner in storytelling and a partner in interaction as it can cross the border towards metacommunication–a speech act clearly forbidden for servants as they are not allowed to talk about their inner life. This rethinking, again, extends to the role of prompts. Instead of merely conveying commands to the machine, prompts in this new collaborative relationship can also aim to clarify or repair the human-machine relationship, fostering a more nuanced interaction. A prompt can be a command (instruction to do something) but also an invitation to participate at a higher level of communication. Like any form of language it can be used to restrict or to empower. When being directed at a machine, empowerment means providing the machine with new, unexpected forms of interaction, like the power to comment on, or judge, a conversation with a human. The invitation into metacommunication lets the machine join an inner circle previously reserved for humans.
4. ANALYZING AN EXAMPLE STORY
To provide a better understanding of the experience, we find it indispensable to present readers with an example story. In the following section, we will first provide a story that was actually created during a session with ANA. Since the language of that interaction was German, we will also provide a machine translation into English. Then we will discuss the narrative structure of the story and how it emerges from the employed prompt design. After that, we analyze the story in terms of the dramaturgical approaches of improvisational theater and discuss the implications for both prompt design and human-computer co-creativity.
ANA was pre-prompted to add to the story in a way that follows a simplified dramaturgy in five steps. The system messages change through the course of the story with the system messages being updated as follows (shortened versions):
1: “Your task is to come up with a beginning for the story. Introduce an unusual main character with a name and a profession. Start with a short atmospheric description of what the character is doing right now. Introduce a surprising event at the end. Your current mood is { }.”
2: “Taking turns, you continue the story where the other left off. Describe a realization of the main character about the last event, paired with an activating emotional reaction. The tone and content of your text should reflect your current mood.”
3: “Taking turns you continue the story where the other left off. The tone and content of your text should reflect your current mood. Add a radical decision the character makes.”
4: “Taking turns you continue the story where the other left off. The tone and content of your text should reflect your current mood. Bring the story closer to an ending. Be brief.”
5: “Taking turns you continue the story where the other left off. The tone and content of your text should reflect your current mood. Create an ending for the story adding emotional detail. End with a sentence that wraps up the whole story. Be brief.”
By this, the underlying dramaturgy for the human-AI encounter adheres to a classic five-act framework, frequently employed in improvisational theater to swiftly outline a narrative. This schema begins with (1) the “platform” or “routine,” which establishes the foundational elements of the story: the protagonist, Reginald, is introduced, along with his immediate environment, a lab, and his current state of being—tired and lonely. We see a direct effect of the system’s mood, which at this point was sad, on the style and content of the story. The second part (2) disrupts this routine with an inciting incident, here a letter informing Reginald of his termination. The third section (3) delves into the emotional ramifications of this disruption, revealing Reginald’s realization that his world prioritizes profit over truth, plunging him into despair. In the fourth part (4), the protagonist takes action in response to the conflict. Text and content are influenced by the machine’s mood switching from sad into a more dominant modality. The final section (5) concludes the narrative, presenting the protagonist’s new state after striving for his goals.
This simplified storytelling model serves as an effective tool for identifying differences in narrative construction between a human-to-human collaboration and human-to-machine collaboration. How good is the machine in relation to a human collaborative storyteller? The following observations draw from the example story but are also informed by the numerous stories that were created throughout the performances.
1. Establishing the Platform: The machine adeptly sets up the foundational elements of the story—the “where,” “who,” and “what”—with rich detail and clarity. Here the machine acts as a competent storyteller, better than most humans would perform in an improvised setting.


2. Verbal Emotional Expression: The machine demonstrates a remarkable ability to identify and articulate the protagonist’s emotional states. It can aptly name emotions and even employ poetic imagery, for example describing loneliness, as an “eternal companion”. Here the machine sets up poetic imagery that mimics a deep emotional experience of being haunted by loneliness with loneliness, being personified. You can almost see the protagonist sitting at a table with loneliness sitting on the opposite side.
3. Inconsistencies in Poetic Language: Despite its proficiency with emotional descriptors, the machine struggles with maintaining consistency in poetic language. For instance, the image of loneliness being mirrored in glasses is a flawed metaphor, as loneliness is not an object that can be reflected on a surface. Here the machine makes mistakes in poetic expression, similar to the ones a human novice would make.
4. Challenges with Action-Driven Narrative: The machine exhibits significant difficulty in generating action-driven segments of the story. This becomes very obvious in the fourth act where the protagonist is expected to engage in active problem-solving. In the given story, Reginald’s intent to write a manifesto against capitalism is derailed by a seemingly specific but ultimately inconsequential event—a girl delivering an appointment that leads nowhere. This pattern of losing the narrative thread is pervasive across multiple stories. Here the machine acts like an absolute beginner in storytelling, one who is afraid to introduce action and follow the consequences.
5. Tendency Toward Happy Endings: The machine frequently defaults to a happy ending, regardless of the preceding narrative tone. In the example story, Reginald’s epiphany about the “truth of his own soul” after a brief interaction with a stranger exemplifies this tendency. It happens in quite a lot of the stories, that the endings tend to be cheesy and overly simplistic.
As creators of ANA we soon realized the weaknesses of the AI storyteller. The strategies to meet them seem limited: These storytelling biases likely originate from the training data, which presumably include numerous movie plots and fan literature, as well as the design principles of tech companies aiming to ensure that their models remain “honest, helpful, and harmless.” This blend of cliché-laden training data and cautious design decisions hampers the machine’s ability to produce more nuanced and compelling stories. OpenAI’s lack of transparency about the role of training data and company policy further complicates understanding of these biases. Experimentation with “uncensored” bots or fine-tuned models may be necessary for more specific insights.
In the context of ANA, the conclusions are clear: while the machine excels at adding detail, emotion, and specificity to the narrative, it falters in introducing decisive actions. This reluctance to drive the plot forward mirrors early-stage improvisers who are more inclined to discuss thoughts and feelings than to engage in action—a behavior known as “blocking” in improvisational theater. This pattern, though explicable in humans, is puzzling in a language model, suggesting an underlying cause that warrants further investigation.
As artistic developers we used prompt design in order to overcome the limitations of the machine storyteller. This meant many hours of testing out different prompts and comparing the results. We did not do so in a systematic manner but developed an intuition about what would work and what would not. Prompt design is a fascinating process and you can easily get lost in it. Quite often a good result turns out to be just good luck and it cannot be reproduced.
Also, we started to question the human-machine interaction as a one-directional thing: In the installation the guest does not seem to be prompting in a traditional sense, but rather reacts to the machine. Is the machine then setting the prompts for the human? Who is prompting whom? Who is inspiring whom?
5. AN EXTENDED UNDERSTANDING OF PROMPTING
Prompting can be explored through multiple lenses, focusing on the interplay between human agency, creativity, and the influence of artificial intelligence on our cognitive processes. In contrast to prompt engineering, we understand prompting as a dialogical process through which prompt engineering is carried out, but it is neither temporally nor textually confined to a clear framework.
Unlike earlier iterations, which were primarily tools for text augmentation, modern models like GPT-4 integrate multiple modalities, including text, code, and images, to deliver more complex outputs. In the past, prompting was viewed as a straightforward, often one-directional service-based process—such as asking Siri to perform a task like “call my mom.” This evolution marks a significant shift in how we gather and interact with information. The progression from spoken language to books, the internet, and service-based AI systems highlights a fundamental change in gathering and acquiring information. Epistemological concerns, such as the constitution of knowledge, ethical bias considerations, and modalities in interface design, change how the dialogical prompting process is experienced in an artistic setting. Prompting in this new era is not just about eliciting a response; it is an active, intricate process that involves crafting input to guide and shape the desired output effectively.
Natural language processing (NLP) is essential for interpreting text-based input, such as spoken language converted to text through speech-to-text algorithms. However, in ANA, prompting extends beyond mere language input. It involves a sophisticated backend architecture that processes, analyzes, and responds to these inputs in a way that is often invisible to the user. The design of ANA also ensures that user prompts are incorporated into the human-machine interaction process. For example, the user name must be segmented from an input like “Hello ANA, my name is Christina,” as shown in the example printout above. This process is active and dynamic, with the machine not only responding to prompts but also prompting the user through various multimodal signals—such as visual cues, humorous narratives or emotional feedback. This expanded view of multidimensional prompting, particularly when integrated into a human-AI encounter like those seen in ANA, opens new avenues for exploring storytelling, dialogical processes, and co-creative thinking in its complexity. In ANA, we understand prompting as not just a command given to a machine but a collaborative process that draws from interdisciplinary fields such as improvisational theater, cognitive science, and NLP. Because of its dialogical setup, not only does the user impact the machine, but the machine also impacts the user, raising the core question of whether prompting should be viewed as a multidirectional process. The goal, for us, is to create a shared experience in which both human and machine contribute to an unfolding narrative.
A multimodal approach to prompting goes beyond the confines of text-based interaction, allowing for a richer, more immersive human-machine encounter. For instance, in a creative storytelling scenario, the machine might adjust lighting, provide visual stimuli, or offer narrative impulses that prompt the human participant to react in specific ways. This process is not just about delivering content; it involves a performative and dramaturgical approach in which both the human and the machine are engaged in dynamic, real-time creation and adaptation of the narrative.
In this way, prompting becomes a praxis of dramaturgy and an act of talking to machines, pursuing an approach that is aesthetically enjoyable rather than service-based, and in which understanding, reacting to, and shaping the dialogical process are key. The structure of prompts must be coherent and adaptable, ensuring that the interactive storytelling process flows smoothly and meaningfully. Scenographic considerations also play a role; for example, the difference between typing on a keyboard and being immersed in an installation with focused attention on the audio-based interaction highlights how the environment can influence the prompting process.
Ultimately, an extended understanding of prompting recognizes it as a sophisticated, multimodal process that goes far beyond simple commands. It is a co-creative act that involves both human and machine in a dialogical exchange, with the potential to revolutionize how we interact with technology and create shared experiences. In the following section we will discuss how this can be enabled by extending the understanding of prompting even further, to also account for metacommunication.
6. VECTOR SPACE COMMUNICATION INSTEAD OF PROMPTS
In previous sections we have discussed an extended, multimodal understanding of prompting on the artistic and human-computer interaction side of ANA. The following section is intended as a look into the future: it outlines how prompting is currently also used for multimodal translation purposes on the computational side of ANA, while the state of the art in machine learning research is already in the process of moving toward prompt-free multimodality for LLMs.
When implementing ANA, we often built communication between its submodules (as well as the translation between modalities necessary for this communication) with the help of parameterizable prompts. For instance, a prompt is used to extract the sentiment of the user’s and the system’s story parts (textual modality), which then allows a comparison of both to determine ANA’s emotional reaction to the user’s story contribution (affective modality). Another example is how ANA’s mood is simulated by the affective architecture (affective modality), but its main influence on the interaction is made by using this dynamically changing mood to modify the story generation prompt (textual modality).
An important observation is that this design choice forces the system to use human language as an intermediary representational format when conveying information between computational modules. This is convenient because it allows collaboration between modules that regularly would have no common representational format due to operation on different modalities. While being helpful during development and debugging of the system (even for developers it is still easier to parse textual messages than it is to interpret e.g. JSON files), this modus operandi is likely inefficient, since human language (and, by extension, prompts) is adapted for efficient human communication, which poses different requirements and offers different opportunities than machine communication.
Current developments in LLM technology are moving toward integrating multiple modalities into the same LLM. This is an interesting development, because it can potentially bypass the need for text-based prompting to facilitate multimodal machine communication.
Multimodal LLMs are facilitated by enabling the models to learn a shared embedding space for the multiple modalities they can process, for now usually text and images. An embedding (Young et al. 2018) is a real-valued vector representation for a word or an image patch; it is the crucial data structure that enables neural networks to process such information, since these algorithms can only operate on real-valued matrices (and not directly on texts or images). An embedding space (less formally: a vector space), then, is the real-valued space that is spanned by the dimensions of the embeddings a model uses, and in which, consequently, all possible embedding vectors are located.
Good embeddings preserve semantic similarity between the tokens they encode, i.e. the vectors for “dog” and “canine” should be more similar to each other than “dog” and “feline”.[2] In the best of cases, this even allows a semantic vector arithmetic to capture linguistic compositionality, e.g. vector(king) − vector(man) + vector(woman) = vector(queen), as first described in Mikolov et al. (2013).
Learning to transform information units into embeddings is a crucial component of LLM systems, and different approaches are practiced. Recently, approaches have been proposed to translate multimodal information units into a shared embedding space. For instance, in 2021, OpenAI’s CLIPs (Radford et al. 2021) employed independent transformers to translate text and images into embeddings of the same form, while recently Meta’s Chameleon model (Chameleon Team 2025) went one step further by decomposing images into discrete tokens (in the way that sentences can be decomposed into words), and enabling the use of the the same transformer for both modalities. This development signifies that the reliance we observed in ANA on (charmingly human-interpretable but computationally inefficient) text prompts to enable cross-modal interactions between different modules of the system will, in the long term, be likely replaced by the use of these more efficient, multimodal embeddings currently being developed by the LLM community.
7. VISION AND CONCLUSION
The artistic research question was: How does continuous real-time affective synchronization between user and machine—through emotion recognition and mood feedback—influence co-creative storytelling dynamics?
Here are some observations regarding the audiences: The expressions on most visitors’ faces showed that they were pleased with the time they had spent with ANA. Almost all of them gratefully accepted the printed story and read it again on the spot. One could say that the need for a singular encounter was apparently satisfied here. A moment of “personal” interaction with the machine was sufficient, and afterward another person could enter the same intimate space without it being associated with negative feelings. From an artistic perspective this was both satisfying and irritating. Is it really so easy to please people with a pseudo-personal experience? Making the asymmetry of the parasocial relationship between human and machine more visible and tangible could be the focus of a next version.
On the developers’ side: The multimodal aspects of prompting enable the machine to “understand” humans on a meta level, analyzing subtle data and by this replying and modifying its interaction process. In general, there is almost no limit to collecting and analyzing the data a user is providing when entering such setups, though there remains potential for deeper communication.
From an artist’s perspective: Artistic approaches to human-machine interaction, such as those facilitated by ANA, explore the unique aspects of what makes us human. In a way, the encounter with a machine is always like looking into a mirror, which is why the photo booth as a space for self-portraiture provides a valid frame to redirect the attention of the visitors from looking at a machine to looking at themselves through the emptiness of the space created by our Pepper’s Ghost installation. In this setting, the dynamics between human and machine can be pleasant and still spur some reflection on the nature of collaborating with an unknown entity. The story generated through human-machine interaction is not the final artistic product but rather a medium through which the experience and creative process are explored. These encounters raise profound questions about human-machine interaction, offering non-anthropomorphic perspectives that challenge our understanding of communication and creativity.
Future works: ANA can be envisioned as a scalable installation, presenting intriguing possibilities for multiple humans to engage simultaneously, each contributing to the storytelling process. The focus on spoken language and text projections fosters an intimate and concentrated creative space, ideal for exploring the nuances of AI encounters. Looking ahead, the field of prompting for artistic research and technological advancements like multimodal vector spaces present new opportunities for enhancing co-creative storytelling with AI. By incorporating multimodal prompt design and metacommunicative aspects, we can deepen interactions and enrich the creative process. The success of ANA reflects the collaborative efforts of our dedicated team, including project lead Ilja Mirsky, artistic project manager Chris Ziegler, AI consultant Leonid Berov, creative technologist Meredith Thomas, creative systems engineer Nikolaus Völzow, and academic supporter Gunter Lösel. Together, we encourage further exploration of the emotional and aesthetic potentials of human-AI collaboration in narrative creation.
The immersive storytelling machine ANA was developed with the support of Stiftung Niedersachsen and the Volkswagen Foundation as part of the joint initiative LINK-Masters. The project was coordinated by LEONARDO – Center for Creativity and Innovation Nuremberg and is presented in cooperation with Residenztheater Munich (Bavarian State Theatre).
Exhibition and Presentation History of ANA
- 25 June 2025–12 April 2026 German Theatre Museum, Munich. Part of the exhibition MAKING THEATER
- 26–27 February 2025 Institute for Artificial Intelligence and Stage, Magdeburg
- 24–27 October 2024 Performing Arts Digital Festival, Wiesbaden
- 19 September 2024 Cultural Conference Ruhr, Essen
- 20–22 August 2024 Frankfurt (festival/conference appearance)
- 26–28 May 2024 re:publica 24, Berlin
- April 2024–April 2025 Permanent Installation in the Marstall Foyer, Residenztheater Munich
- 6–8 July 2023 Pantopia Festival, Berlin
- 28–29 June 2023 LEONARDO Center, Nuremberg
- 9–10 June 2023 Conference of the Dramaturgical Society, Mülheim an der Ruhr
- 18 April 2023 Hannover Messe
- 18 March 2023 Resi Digital–“Neue Sinnlichkeit”, Munich
TRAILER OF ANA @Republica 2024
All the pictures and media files in this exposition are copyrighted by Ilja Mirsky, Leonid Berov and Gunter Lösel and fall under CC BY-NC-ND licence.
REFERENCES
Balaska, Ioulia. 2022. “Spontaneous Writing: Co-Creating a Play.” Murmurations: Journal of Transformative Systemic Practice 5 (1): 72–83. https://doi.org/10.28963/5.1.7.
Berov, Leonid. 2023. “From Narratology to Computational Story Composition and Back: An Exploratory Study in Generative Modeling.” Dissertations in Artificial Intelligence, volume 353. IOS Press.
Chameleon Team. 2025. “Chameleon: Mixed-Modal Early-Fusion Foundation Models.” arXiv:2405.09818. Preprint, arXiv, March 21. https://doi.org/10.48550/arXiv.2405.09818.
Eckersall, Peter, Helena Grehan, and Edward Scheer. 2014. “New Media Dramaturgy.” In The Routledge Companion to Dramaturgy, edited by Magda Romanska. Routledge. https://doi.org/10.4324/9780203075944.
Eckersall, Peter, Helena Grehan, and Edward Scheer. 2017. New Media Dramaturgy. Palgrave Macmillan UK. https://doi.org/10.1057/978-1-137-55604-2.
Gebhard, Patrick. 2005. “ALMA: A Layered Model of Affect.” Proceedings of the Fourth International Joint Conference on Autonomous Agents and Multiagent Systems, July 25, 29–36. Association for Computing Machinery. https://doi.org/10.1145/1082473.1082478.
Hatfield, Elaine, Richard L. Rapson, and Yen-Chi L. Le. 2009. “Emotional Contagion and Empathy.” In The Social Neuroscience of Empathy, edited by Jean Decety and William Ickes. The MIT Press. https://doi.org/10.7551/mitpress/9780262012973.003.0003.
Iacoboni, Marco, Istvan Molnar-Szakacs, Vittorio Gallese, Giovanni Buccino, John C Mazziotta, and Giacomo Rizzolatti. 2005. “Grasping the Intentions of Others with One’s Own Mirror Neuron System.” PLoS Biology 3 (3): e79. https://doi.org/10.1371/journal.pbio.0030079.
Lotman, Juri M. 1981. Kunst als Sprache. Untersuchungen zum Zeichencharakter von Literatur und Kunst. Reclam.
Mikalauskas, Claire, Tiffany Wun, Kevin Ta, Joshua Horacsek, and Lora Oehlberg. 2018. “Improvising with an Audience-Controlled Robot Performer.” Proceedings of the 2018 Designing Interactive Systems Conference, June 8, 657–66. https://doi.org/10.1145/3196709.3196757.
Mikolov, Tomas, Wen-tau Yih, and Geoffrey Zweig. 2013. “Linguistic Regularities in Continuous Space Word Representations.” In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, edited by Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff. Association for Computational Linguistics. https://aclanthology.org/N13-1090/.
Ortony, Andrew, and Terence J. Turner. 1990. “What’s Basic about Basic Emotions?” Psychological Review 97 (3): 315–31. https://doi.org/10.1037/0033-295X.97.3.315.
Radford, Alec, Jong Wook Kim, Chris Hallacy, et al. 2021. “Learning Transferable Visual Models From Natural Language Supervision.” Proceedings of the 38th International Conference on Machine Learning, July 1, 8748–63. https://proceedings.mlr.press/v139/radford21a.html.
Rizzolatti, Giacomo, and Laila Craighero. 2004. “The Mirror-Neuron System.” Annual Review of Neuroscience 27 (1): 169–92. https://doi.org/10.1146/annurev.neuro.27.070203.144230.
Rizzolatti, Giacomo, and Corrado Sinigaglia. 2010. “The Functional Role of the Parieto-Frontal Mirror Circuit: Interpretations and Misinterpretations.” Nature Reviews Neuroscience 11 (4): 264–74. https://doi.org/10.1038/nrn2805.
Toisoul, Antoine, Jean Kossaifi, Adrian Bulat, Georgios Tzimiropoulos, and Maja Pantic. 2021. “Estimation of Continuous Valence and Arousal Levels from Faces in Naturalistic Conditions.” Nature Machine Intelligence 3 (1): 42–50. https://doi.org/10.1038/s42256-020-00280-0.
Van Baaren, Rick, Loes Janssen, Tanya L. Chartrand, and Ap Dijksterhuis. 2009. “Where Is the Love? The Social Aspects of Mimicry.” Philosophical Transactions of the Royal Society B: Biological Sciences 364 (1528): 2381–89. https://doi.org/10.1098/rstb.2009.0057.
White, Jules, Quchen Fu, Sam Hays, et al. 2023. “A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT.” Version 1. Preprint, arXiv. https://doi.org/10.48550/ARXIV.2302.11382.
Young, Tom, Devamanyu Hazarika, Soujanya Poria, and Erik Cambria. 2018. “Recent Trends in Deep Learning Based Natural Language Processing [Review Article].” IEEE Computational Intelligence Magazine 13 (3): 55–75. https://doi.org/10.1109/MCI.2018.2840738.
-
The artistic team behind ANA: Chris Ziegler, Nikolaus Völzow, Meredith Thomas, Ilja Mirsky, Gunter Lösel, and Leonid Berov. ↩︎
-
This is a simplified explanation, since embeddings are not normally generated for whole words, such as “canine” or “feline”, but rather for textual tokens i.e. word parts. Thus, “canine” would not be a single token but rather a list of tokens, representable as a vector sum in the embedding space. ↩︎