To look into...
models of artificial neurons / memory structures
sequential memory structures in circuitry & analog structures (e.g. flip-flop like positive feedback behavior)
recording / inscription methods - forms of writing
reference: the Master Algorithm
^^^^^^^^^^^^^^^^^^^
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was first organized in 2010 as a test of the progress made in image recognition systems.
The organizers made use of Amazon Mechanical Turk, an online platform to connect workers to requesters, to catalog a large collection of images with associated lists of objects present in the image. The use of Mechanical Turk permitted the curation of a collection of data significantly larger than those gathered previously.
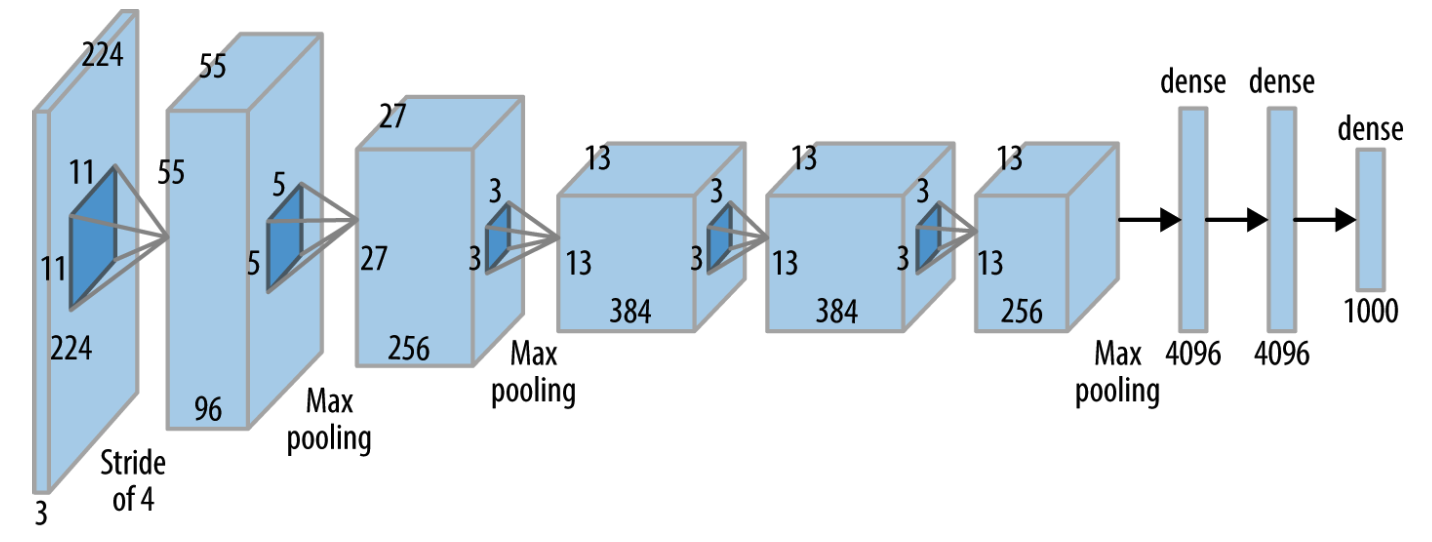
In 2012, the AlexNet architecture, based on a modification of the LeNet architecture (1988) run on GPUs, entered and dominated the challenge with error rates half that of the nearest competitors. This victory dramatically galvanized the (already nascent) trend toward deep learning architectures in computer vision.
Since 2012, convolutional architectures consistently won the ILSVRC challenge (along with many other computer vision challenges). Each year the contest was held, the winning architecture increased in depth and complexity. The ResNet architecture, winner of the ILSVRC 2015 challenge, was particularly notable; ResNet architectures extended up to 130 layers deep, in contrast to the 8-layer AlexNet architecture.
Very deep networks historically were challenging to learn; when networks grow this deep, they run into the vanishing gradients problem. Signals are attenuated as they progress through the network, leading to diminished learning. This attenuation can be explained mathematically, but the effect is that each additional layer multiplica‐ tively reduces the strength of the signal, leading to caps on the effective depth of networks.
The ResNet introduced an innovation that controlled this attenuation: the bypass connection. These connections allow part of the signal from deeper layers to pass through undiminished.
<
<
<
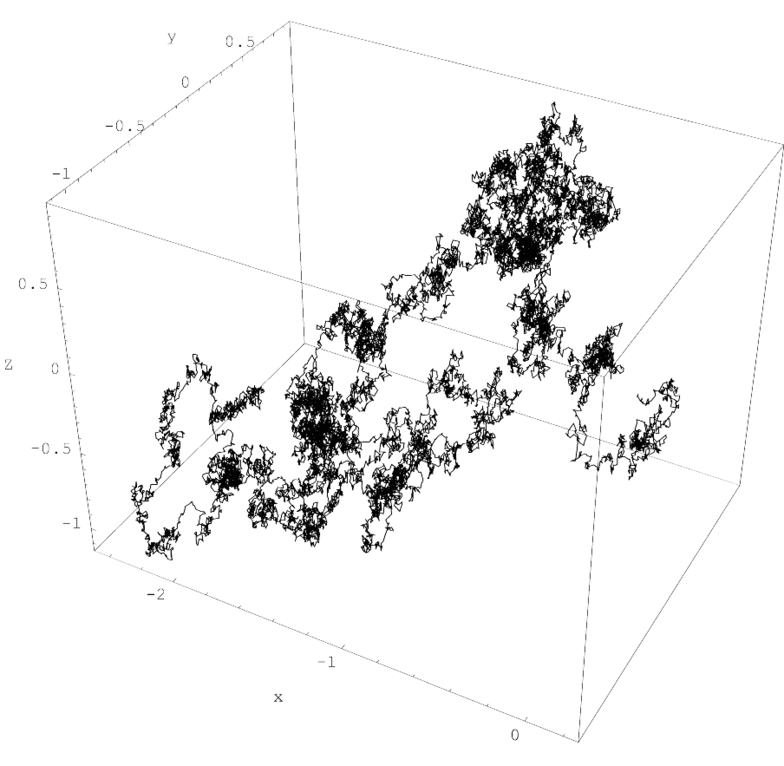
A single realisation of three-dimensional Brownian motion for times 0 ≤ t ≤ 2. Brownian motion has the Markov property of "memorylessness", as the displacement of the particle does not depend on its past displacements.
<
<
<
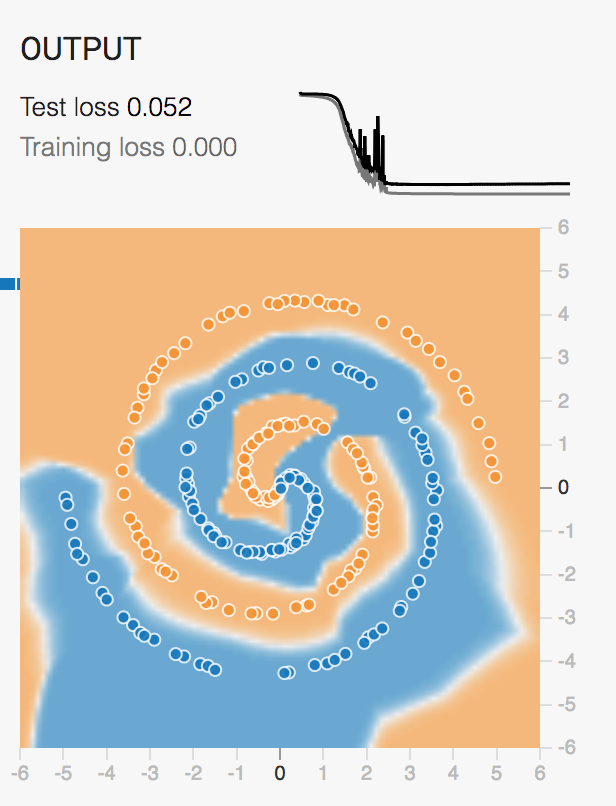
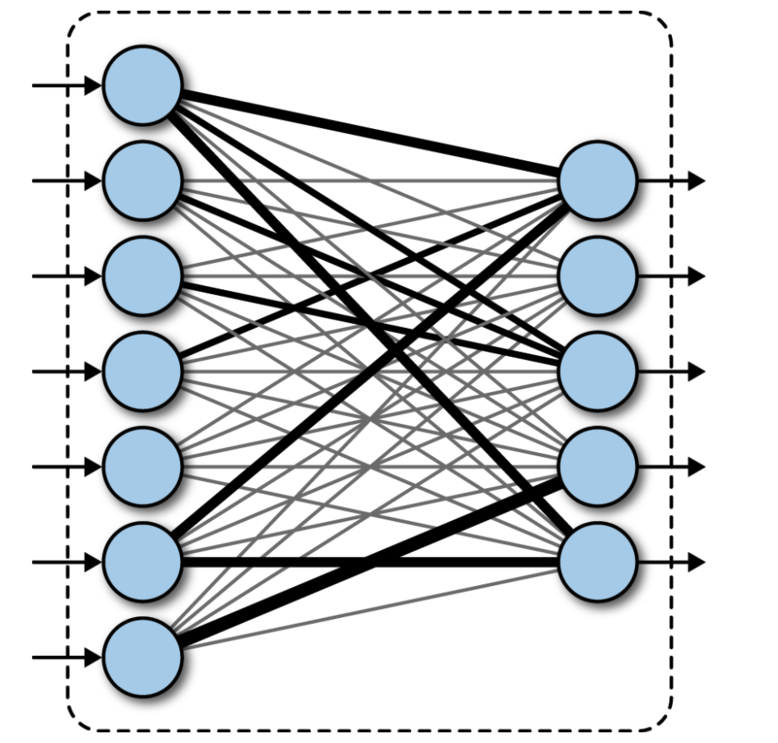
Simple Perceptron
A perceptron can learn patterns in linearly separable datasets. Usually by fitting a line.
Depending on activation function, different types of classification/prediction can be achieved.
Start with a randomly initialized weight vector W;
while there exist input samples that are
misclassified, do;
Let X be the misclassified input vector;
W = W + Y\*η\*X;
end-while;
... it seems most "artificial neural networks" can be thought of as nested linear compositions of nonlinear functions ...
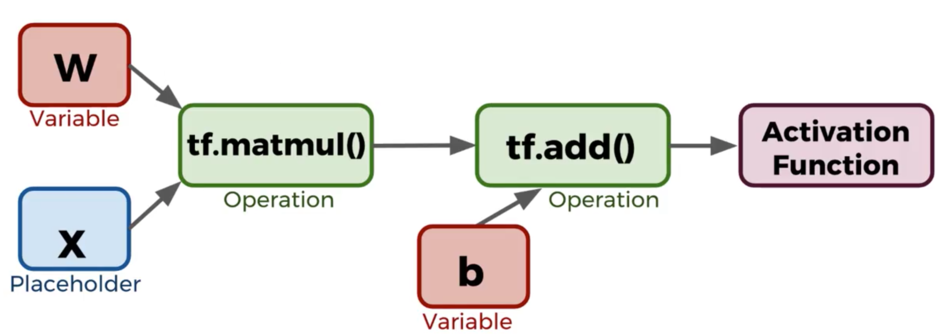
weights and biases
sum(w*x) + b = y
(y - yprediction)**2
the squared term exponentially increases the error for higher error values
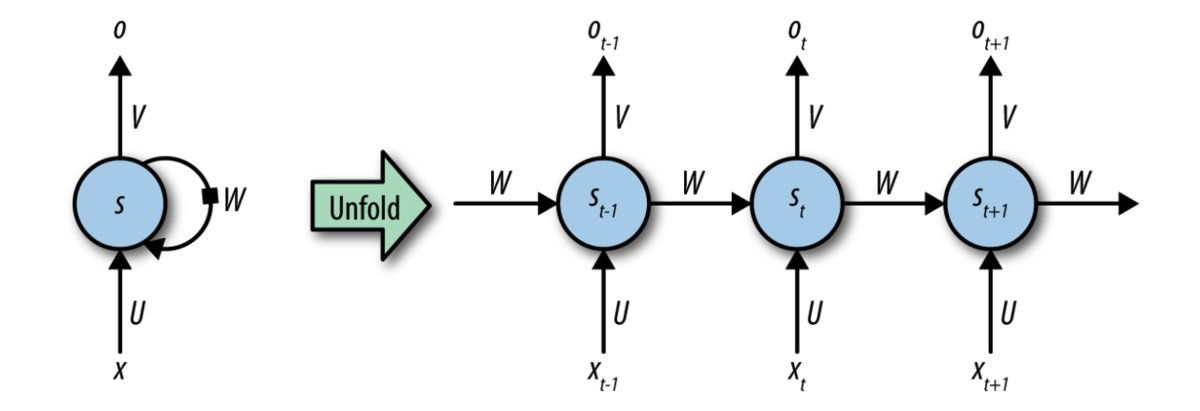
A recurrent neural network (RNN). Inputs are fed into the network at the bottom, and outputs extracted at the top. W represents the learned transformation (shared at all timesteps). e network is represented conceptually on the le and is unrolled on the right to demonstrate how inputs from di erent timesteps are processed. Recurrent neural network (RNN) layers assume that the input evolves over time steps following a defined update rule that can be learned/optimized.
The update rule presents a prediction of the next state in the sequence given all the states that have come previously.
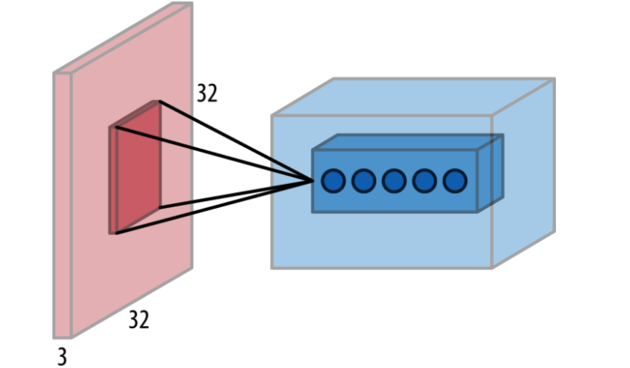
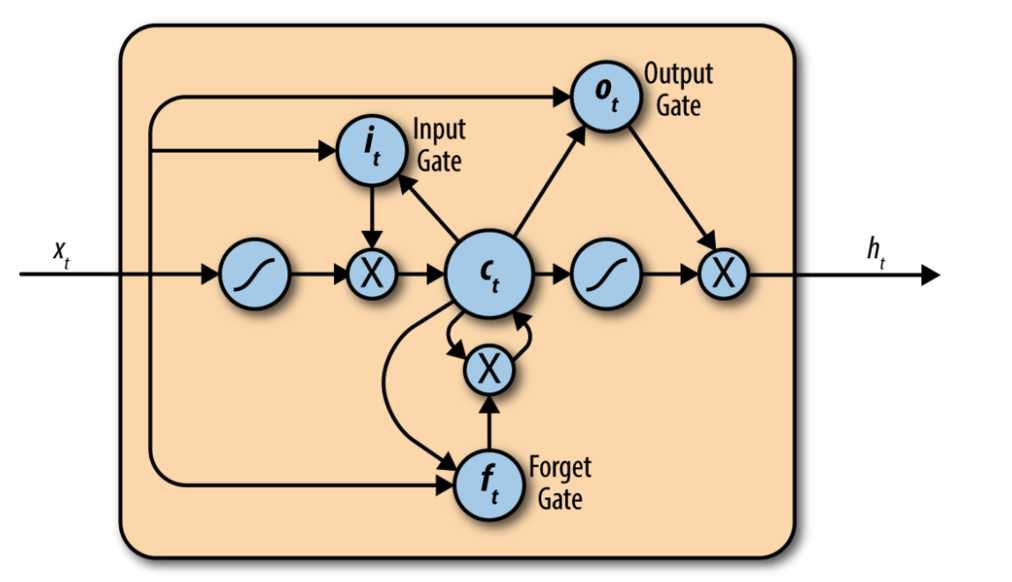
One of many variations on a long short-term memory (LSTM) cell, containing a set of specially designed optimizable operations that attain much of the learning power of the RNN while preserving influences from the past.
Standard RNN layers are incapable of including influences from the distant past in their optimal bodies. Such distant influences are crucial for performing, for example, language modeling. The long short-term memory (LSTM) is a modification to the RNN layer that allows for samples deeper in the past of a sequence to make their memory felt in the present.