{POZ, 14_11_18}
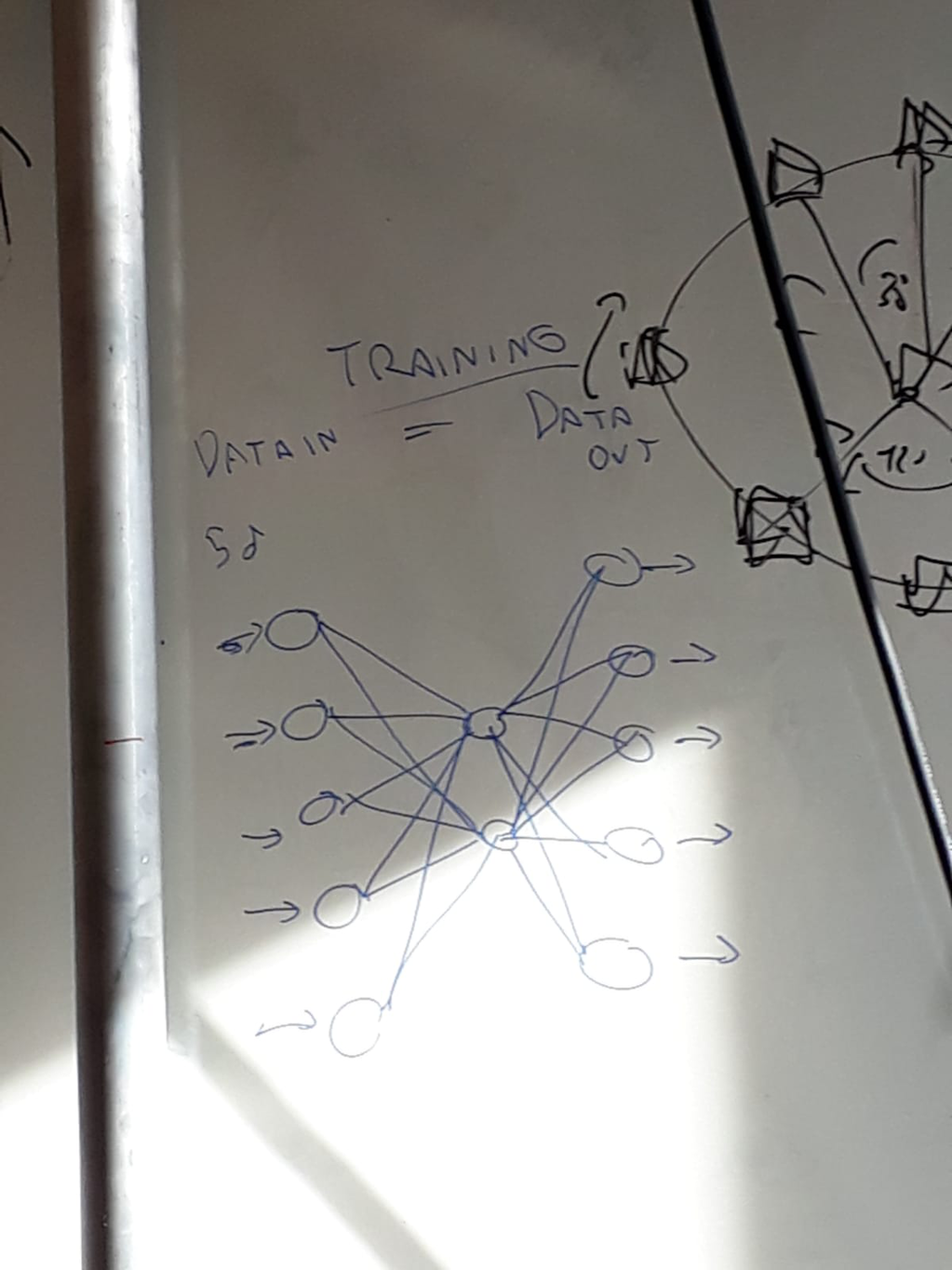
During this meeting the topic of dimensinoality reduction came up and a few methods to reduce the dimensions of a dataset were discussed. Jonathan then brought up the autoencoder, a type of artificial neural network used to learn efficient data codings in an unsupervised manner. Typically, an autoencoder has an input layer, an ouput layer and one or more hidden layers connecting them, but with the ouput layer having the same number of nodes of the input layer, and with the purpose of reconstructing its own inputs. The autoencoder therefore consists of two parts, the encoder and the decoder. The intermediate, compressed image is referred to as code or latent representation (Wikipedia).
Cutting the structure
Drawing an analogy from anatomical practices, Jonathan expressed his interest in exploring the structure of this kind of model by cutting or dissecting the network in parts. Once the network is trained, if we chop off its left side we obtain a synthesizer. Cutting off its right side, we get a compressor / dimensionality reduction.
{function: contextual}
{POZ, 14_11_18}
Dissecting the process
I think it could also be interesting to observe the process of encoding and decoding while the learning itself is still running. Let's say, starting from a 'zero learning', feeding an input stream (a movie, for example) and look at the ouput while the network is learning. Kind of 'dissecting the process of learning', to maintain the anatomical analogy ...
{function: comment}
[JR]
I'm really interested in this also in terms of these anatomical practices, because there's really this act of cutting. And this is kind of interesting for thinking about artificial neural networks in general, you know, this act of cutting and how that changes the data in and the data out. And the possibilities of synthesis versus compression/convolution etc.
[DP]
that's a very interesting idea. Train neural networks and then cut em up, as you would do when studying some tissues in a human body. You make a very thin slice and you put it under the microscope and see what it does.
{persons: [jr, dp]}
{POZ, 14_11_18}
NSynth is a WaveNet-based autoencoder to synthesize audio
{function: comment}
{JR}
Creating this bottleneck here, when training the network you're creating a compressed encoding of the salient information. So then what you do, once you've trained it, you chop off one side of the network. If you chop off this side of the network it becomes a dimensionality reduction, from 5 to 2. If you chop off this side of the network it becomes a synthesiser. A parametric synthesiser basically: two parameters controlling five. And this is usually not used for classification. I've seen it recommended to be used for dimensionality reduction. The example I always see with it was with training it on an image dataset. Like, for example, if you train it on a set of butterflies and then you chop off the front you get a parametric butterfly generator. which can also be used for sound synthesis, that's what I was kind of interested in it for.