{dp, 200124}
I think you're making a good point here. I didn't notice the use of the workd "listen" in Hanns Holger's text, but you are right, now that you have pointed it out, it does feel "strange" in some way.
I also share your attitude in not thinking of the porcesses or algorithms I compose in my works as tools through which I listen or by which I implement a way of listening.
And, in general, I also avoid to apply human biases, or
expectations. "I would like the algorithm to /listen/ or /detect/ that particular sound". That is, I would rather compose my work such that the algorithm is capable of its "own" listening. Instead of telling how to "listen", decide a priori what is important or what is an "event" that should be recorded or reacted to. A priori in the sense that these, at least that is how I feel, are decisions taken from a perspective external to the algorithm's own unfolding, external to the process of interaction with the algorithm during its development. I would like to be "surprised" of what will in the end be "captured' or be in some way critical for the processes' evolution. I would rather try to "challenge" my listening rather then confirming it.
I writing this I realize that of course, the above is a quite "ideological" position. In reality the composition of such processes will inevitably emerge through an interaction of actors: me, the programmer and composer, the code, the space etc. So to think that, the aesthetic artefact resulting from this interaction will not be influenced or in some way biased by my (human) aesthetic. It will be entangled in it. Still, I think it's a matter of attitude, but an important one. A perspective one takes up or employs while looking or listening to things.
So, even if I understand, I do not share your solution of trying to implement a sore of "human listening" into "my" segment. I would rather try to go the other way... ↗
{author: DP, date: 200124, function: comment, keywords: [listen, listening, algorithm, space, staircase, acoustics, human, implementation, design, composition]}
{poz, 200210}
I agree, nevertheless I think these metaphors we use are interesting because they also influence the way we think of our programs, and then how we implement them. Indeed this page was an experiment in purposely adopting a perspective that I feel 'unnatural', to see where it would lead. I tried to make this a bit more explicit in my response to Hanns Holger on the right side of this page. About the world 'listening', I think it is so broad that it can be used and understood from many different angles. And the act of listening happens at various levels. For example, listening is one of the means we use to interact with our programs. Probably the reason I felt the word 'strange' at first was because I intended it in a too narrow sense, that of 'human listening' or discerning things through sound, making sense of an environment through ears. ↗
{author: POZ, date: 200210, function: response, keywords: [listen, listening, algorithm, space, staircase, acoustics, human, implementation, design, composition, interaction]}
{hhr, 200210}
I agree that (human) listening is a differentiated (and very complex) process. I think it would be problematic to exclude it from the composition, hoping instead that any algorithmic transformation is as good a replacement. It does not need to appear as the highest principle, but put into perspective. Naturally, we cannot listen-to-intervene while the installation is running—and also, no two humans listen in the same way—but we can use audibility as a guiding principle in the algorithmic construction. I like the three assumptions from the very introduction of Trevor Wishart's Audible Design:
- Any sound whatsoever may be the starting material for a musical composition.
- The ways in which the sound may be transformed are limited only by the imagination of the composer.
- Musical structure depends on establishing audible relationships amongst sound materials.
{author: HHR, date: 200210, persons: Trevor Wishart, function: comment, keywords: [listening, algorithm, space, staircase, acoustics, human, implementation, design, composition, imagination, relationships, structure]}
Some days ago we put together a brief description for our Kunsthaus project (now appearing in the first page of this exposition). Originally Hanns Holger wrote a proposal for this text. In reading his proposal, a specificic word somehow stuck with me
Four artists listen into the storeys using real-time computer algorithms, taking an acoustical image of the visitors’ movements, forming four individual reactions.
something sounded a bit out of place - at first, I had the feeling the word listen was put in a weird position. I mean, somehow it just sounded strange to me. I guess that's because I never thought of algorithms as something through which I listen. this made me think about which other different meanings the word listen could take in my work in the staircase, and how the act of listening might be "bended" or "reintepreted" there ↗
{author: POZ, date: 200124, function: contextual, keywords: [listen, listening, algorithm, space, staircase, acoustics]}
try to isolate the "sound exceptions" (sounds with less common characteristics). Using a linear regression algorithm to find the medium values, or "common sound events". then exceptions would be events far from the common ones
time doesn't make much sense as a value that is used in linear regression. Nevertheless it was useful as a test to display results chronoligically inthe carthesian plane. Exceptions, here, are only exceptional in their loudness
{kind: note }
One method to find sound exceptions in a time series:
- extract events from raw signal
Two RMS with different time windows. If the energy in the shorter time frame exceeds the energy of the larger one by a certain amount (threshold) we have a sound event. ↗ - predict linear function
Through inear regression model (least squares method). Each point P(x,y) is a sound event where x = amplitude, y = time. ↗ - find least mediocre events
Furthest points from the line
{author: POZ, date: 200124, function: description, keywords: [listen, listening, algorithm, space, staircase, acoustics, listening space, exceptions, implementation, counting, pseudo code, event, linear regression]}
---
meta: true
persons: [HHR, POZ, DP, JYK]
date: 200124
author: [POZ, HHR]
artwork: ThroughSegments
keywords: [listening]
---
{hhr, 200211}
The event detection seems to work really well, now I'm tempted to do this with just RMS as well. It's also nice visually to see the deviations, which as I understand are deviations from the RMS ratio. Do you have a particular idea in mind what you are going to do with these deviations?
{author: HHR, function: comment, keywords: [rms, event detection, deviation]}
Usually I find terms related to human perception (listening, vision, etc) a bit too stretched when applied to computer or algorithms. But in this case it might be stimulating to think through this metaphor. I'd be especially interested in trying to implement some specific way of listening into an algorithm, for example: listen to the people walking, identify different people and count the steps for each of them. This is something quite natural for us humans, but kind of tricky to implement algorithmically. I'd like to see how something like this could be formalised, and (since results will necessarily me imperfect) to see what new patterns emerge out of this (impossible) translation. Which new forms take place when an algorithm "listens".
So I was listening again to David's recording, thinking which mode of listening I should try to implement. In the moment I was listening, but in a distracted way. my attention was especially attracted back to the recording by "exceptional" sound events. So I decided to try to implement a "distracted listening" that looks specifically for exceptions.
{author: POZ, date: 200124, function: contextual, keywords: [listen, listening, algorithm, space, staircase, acoustics, listening space, sense-making, coding, implementation, counting]}
what can we listen into the storey?
- doors slamming
- people walking
- people chatting
can an algorithm "listen" to these? ↗
or
what can an algorithm listen?
or
how can it listen?
- segmenting
- measuring
- counting
detecting sound events using this method was initially tricky, because the staircase resonates quite a lot: I was getting many (false) events from the reverb tails. Since the staircase reverb is a 'dark' one (it resonates mostly in the lower spectrum), one quick fix was to high-pass the signal before measuring the rms. From what I found out, high passing at 3k is a good compromise for removing unwanted tails, while still letting through enough of the sound events to be detected.
{kind: note }
{hhr, 200124}
A bit tangential, and not an answer, but there was this project: Humanising Algorithmic Listening.
Perhaps to clarify what I meant in the synopsis: Of course we as artists are probing the space, we are listening to what is happening there, we understand the space as a listening space. And then we try to implement some of our ideas in terms of algorithmic perception or "sense-making". This is not to suggest that the algorithms are performing anything related to human listening, which is a far more complex mechanism and multiple stages. Also, "making sense" of course could also be questionable when attributed to an algorithm, but I want to say we as artists make sense through our coding. ↗
{author: HHR, date: 200124, function: comment, keywords: [listen, listening, algorithm, space, staircase, acoustics, listening space, sense-making, coding]}
{poz, 200210}
yes, that's quite close to how I interpreted your synopsis between the lines. I like quite much the expression you are using here 'making sense through coding', it's quite comprehensive but still very open. I guess what I tried to do in this page was to focus on the word 'listening' to see which ideas it would bring up. I found curious that 'listening' is not among the first things I think about when approaching a space from an artistic side. I tend to think more in terms of 'coupling' for example - I believe this was another word that came up in our last skype meeting (Jan 24th). In order to couple
things of course you look for affordances, for opportunities to create relationships. And in this part, listening is involved quite much. You also listen after you implemented a relationship, to understand if it 'makes sense' or if that relationship is made perceivable somehow. You listen to understand if it integrates in the environment. So 'listening' is always kind of in the background - some ways of listening at least - but rarely a focus - shall I say foreground? ;) - for me.
I wanted to see what happens if I make 'listening' a focus instead. Reading back now, I think that I based this little experiment on a definition of listening that is a bit too specific. Discerning things through sound, making sense of an environment through ears.
Anyway.. It might be a over-simplification, but I had the feeling that focusing on this particular aspect of 'listening' brought me to think more in terms of segmentation and categorization. This is also reflected in the small code experiment I was writing; first it 'segments', then (tries to) 'categorize', to separate 'common events' from 'exceptional events'. These are things I normally tend not to do, or even to avoid sometimes. When I try to couple things, I don't want to segment or categorise, because coupling should work in a more 'abstract' or 'mechanical' way. It's a process that should 'make sense' without 'having a knowledge' of what it is put in relation with. I don't know how to express it, but in my understanding it's an idea that is a bit orthogonal to that that of segmentation and categorisation. But I think in this work it's interesting for me to include also these processes in some form.
{author: HHR, date: 200124, function: response, keywords: [listen, listening, algorithm, space, staircase, acoustics, listening space, sense-making, coding, affordances, relationships, coupling, background, foreground, segmentation, categorisation]}
here I tried to "tune" the event detector to detect single walking steps. kind of tricky as it is now, maybe it needs some adaptive threshold
trying to detect single steps:
- short rms = 250 ms
- large rms = 1000 ms
- threshold = -74 db
{hhr, 200202}
Based on the deliberation that it is unlikely without provisions that all four layers are silent at periods in time, and given that we all rely on listening into the space without just picking up what each of us is adding to it, I want to propose two mechanisms to ensure and stimulate a regulation of overall activity in the space and to permit for layers to pick up "plain" sound. These two mechanisms could be called "common listening" (CL) and "independent activity budget" (IAB).
Common Listening builds on the previously discussed idea that there could be temporal bridges that allow to put to rest all layers in a cooordinated way. Let's say, there could be silence for half a minute, or for 25% of the time, thus to gather 15 minutes of non-interfered material, one hour passes. Coordinated means, each layer may ask for this occasion, and there is a protocol in place for all layers to agree on such action. A rule could specify that each layer may only ask for common listening successfully once in a given period of time—for example, once every twenty minutes or half an hour.
The protocol could follow one I developed in the schwärmen+vernetzen project for a similar task: There are a number of individually running nodes, and we need a way for one node to request coordinated action via OSC over the network. It works as follows:
- each layer has an id (1, 2, 3, 4), and an internal transaction counter (monotonously increasing). The tuple (id, txn-count) identifies a network request, and is used for all related messages, no matter who sends the messages. Additionally, each message also always contains the sender's id, so that one does not need to match the socket address of the sender to identify the sender.
- common-listening may require a short preparation, dependent on each layer. For example, one layer may want to fade out its sound production over a few seconds before it becomes silent, another layer is performing a "counting" and also needs a few seconds before it can move into the new state. So we add a minimum-required-delay parameter for each layer.
- Say, layer 1 wants to request common listening. It is its first request, thus the txn-count is also 1. It chooses a minimum-required-delay parameter of four seconds. It sends out a message /begin-cl, 1, (1,1), 4.0 to all other layers. The first argument is the sender's id, the second argument is the tuple (layer-id, txn-count), the third argument is the minimum-required-delay parameter.
- Shortly afterwards that message arrives at layers 2, 3, 4. None of them has objections, and so in an indeterminate order, these three layers will all respond bith /ack-cl messages. For the sake of the example, say layers 2 and 3 need only two seconds for the minimum-required-delay parameter, whereas layer 4 requests five seconds. The three messages (going to all layers) are thus: /ack-cl, 2, (1,1), 2.0 and /ack-cl, 3, (1,1), 2.0 and /ack-cl, 4, (1,1), 5.0.
- Since each layer has now received acknowledgements from all other layers, the request is successful, and each layer calculates the actual preparation delay as the maximum of all requested delays—five seconds. Each layer comes to a rest within these five seconds, after which the common listening begins (silence across all layers). The duration of that action is either an agreed-upon constant, or if it is variable, it would have formed a fourth argument to the /begin-cl message.
- After that period has expired, the layers return to their normal mode of sound production.
There are additional rules to ensure that the process works correctly: Message replies time out after a fixed period (a few seconds probably). For example, in the above example, if there was a problem with layer 3 and it did not respond with /ack-cl, this failure to acknowledge the request is implicitly taken after the timeout period, so if there is a bug in layer 3 or the computer is off or frozen for some reason, the remaining three layers can still enter successfully into the common listening mode. Also, since network traffic is asynchronous, if by chance two layers 1 and 2 both decide approximately at the same time to issue a /begin-cl message (before knowing about the other's request), then the request is automatically aborted, the layers choose a fuzzy amount of time to wait (a few seconds) and retry the request.
Global parameters:
- maximum period of time that has to pass before the same layer can make another request
- timeout period for missing reply messages
- maximum allowed minimum-required-delay time
- duration of common-listening. Alternatively, this is a parameter of the /begin-cl messages, and instead we define the minimum and maximum value this parameter can take.
If the need arises, we could add a message /deny-cl if a layer must be capable of denying a request for common-listening. I can't think of a case where this is needed, but if we add it, it should be a very rare case and normally layers should not deny requests.
{author: HHR, date: 200202, function: proposal, keywords: [common listening, listening, communication, protocol, OSC, network]}
{hhr, 200202}
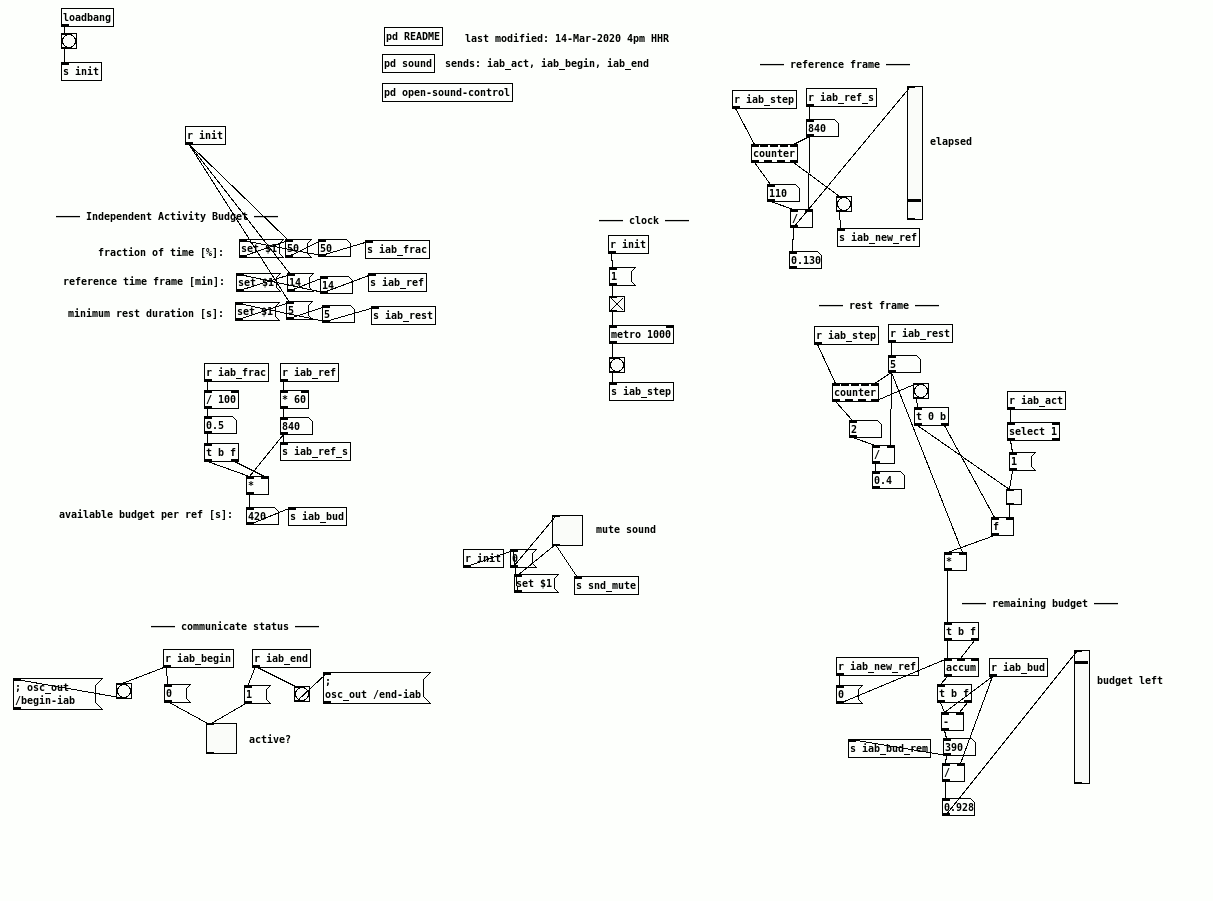
Independent Activity Budget is a complementary mechanism that does not require synchronisation between the layers. The idea is very simple: If all layers produce sound all the time, there is never a moment where we can hear just what happens in the space, and also the installation will be quite stressful, especially for people that are in the vicinity of the installation for longer periods of time. Furthermore, it would mean that we can never hear the different possible sets of layers playing alone, in pairs or in groups of three, so we would lose a lot of potential of transparency, as well as potential for listeners to experience the spatiality and verticality of the space. Another goal is to prevent that there might be prolonged imbalance of the four voices. ↗
The IAB just states that over a given period of time, each layer can only be active for a maximum fraction. For example, we could say that within a window of half an hour, each layer must ensure that it emits sounds for a cumulative period of no more than fifteen minutes or 50% of the time. When and how ↗ that budget is used is the responsibility of the layer itself. This rule is implemented by the layers independently and simultaneously, and thus with the example of 50%, by statistics there is a chance of (1/2)4 = 1/16 or 6.25% that at any moment all layers are resting (roughly four minutes for each hour). It's also 6.25% probable that at any moment all layers are active; it's 25% probable that exactly one out of the four layers is active; it's 25% probable that exactly three layers are active; it's 37.5% probable that two layers are sounding. ↗
Global parameters:
- the fraction of time (e.g. 50%)
- the reference time frame (e.g. per half-an-hour)
- the minimum duration of a rest. E.g. we don't count a silence if a layer mutes every second sample frame :) It should probably relate to the reverberation time of the space and be in the order of five seconds or more.
Knowing how many layers are active is a useful information to others, for example if layer X knows that all other layers are silent, it could perform a particular listening act or adjust its feedback parameters, knowing that the currently added sound solely comes from itself. Therefore, I suggest to add the messages /begin-iab and /end-iab that each layer emits to inform the others. ↗
{author: HHR, date: 200202, function: proposal, keywords: [independent activity budget, communication, protocol, OSC, network]}
{hhr, 200314}
I implemented a simple mock layer in PD that produces the IAB behaviour and sends its status to another OSC socket.
{kind: note}
{poz, 200210}
I agree with the idea of implementing this independent activity budget. Even though I would be more in favour of going into a more systemic approach, rather than predetermined periods of activity, I am also not against it. The strategy you propose is probably easier to realise and more reliable in terms of result in time (I mean, we will be quite sure that statistically it will just work as you described)
{author: POZ , date: 200210, function: comment }
{poz, 200210}
"When and how the budget is used is the responsibility of the layer itself". I'm trying to think of what kind of parameters could influence this when and how, besides looking at the others activites and shut down when they are playing and coming back up when they are quite (the first obvious idea that came to my mind). What I want ot say is that maybe we want to think to include some other informations in our protocol, that could help in providing more parameters to define "when" and "how". The first thing that occurs to me is, for instance, informations on the spectral content of what is being pplayed, or some kind of temporal information (static / irregular etc.)
{author: POZ , date: 200210, function: comment }
{poz, 200210}
I like quite much your suggestion of having periods of 'common listening', moments where sound production is suspended and we enter all together in this listening mode. I'm also in favour of the protocol you suggest based on request / ackownledgement, I find it resonates well with the idea of 'through segments'
{author: POZ , date: 200210, function: comment}
{poz, 200210}
Somehow I find intriguing the idea of detaching this moment of 'listening' from all the other possible combinations / situations we will have in the work. I think it would be nice if these listening periods are also an opportunity for the segments to 're-organise', so that when they come back later this 'act of listening' or 'digesting' is made perceivable in a way.
{author: POZ , date: 200210, function: comment}
{dp, 200210}
I for sure understand the problem you are pointing out. And we sure do not want to stress the people working there. I also understand how you want to solve the problem: you suggested an system that will quute surely work. But, at least in this formulation, your systens doesn't take into account the quality of the sound "produced" by each segment. It could be that the sound is very soft, only audible in the vicinity of the loudspeakers. Or very sparse. I don't think a simple On/Off mechanism based on pre-determined statistics works here. Sure we can do it like this, but it feels quite rough.... ↗
{author: DP , date: 200210, function: comment }
{hhr, 200210}
Sure we can add more information (e.g. spectral), but I would suggest to begin with the most basic and reduced approach first, until we determine that we do need that additional information, because it puts extra work on our implementations and the use of computation power.
{author: HHR , date: 200210, function: response}
when and how
could be related to
- sounds from the environment
- sounds from other segments
{hhr, 200210}
My goal is to create a starting situation here. If we don't like the resulting behaviour (or it is imbalanced), we can adjust and tune it after the fact. I don't think a clear cut on/off measure is bad in this situation. If we then feel that we need to accommodate faint sounds in this model, we can make the model more complex at a later stage (but we already have something working in place).
{author: HHR , date: 200210, function: response}