{hhr, 200508}
Yes, the covid time-out has quite a strike. On the other hand, I found quite interesting how this online space became something of a simulacrum for the mixture between our thought spaces and the staircase. I feel that when I am here, browsing or editing, my thoughts are with the real space, somehow I always have it present when I meet here.
---
meta: true
artwork: ThroughSegments
author: poz
keywords: [test, prototype, sound, rendering, experiment]
---
{POZ, 200312}
this page collects materials relative to a tentative first mockup for our KH installation. We were (?_ supposed to have a first meeting altogether tomorrow in Graz, but due to the covid situation this is still unsure at the moment of writing
non real time
Another thing I thought of is to introduce some sort of memory in the system, in order to decouple the process from the "here and now" and from this feeling of "direct trigger". So I introduced a buffer, and started thinking about strategies to deal with signals from the past. One of the first questions for me was how to read these signals back. I wanted to avoid windowing, so I thought about starting reading at zero crossing. And I was using a rudimental segmentation algorithm to isolate, for example, steps and play them back. Nevertheless this sounded a bit cheap, like a classic sampling machine. I thought to use smaller periods and I realised I could even start and end reading at successive zero crossings. I ended up with a sort of stutter / granulator that has some interesting sound qualities. Then I realised I could modify any of its parameters, as long as I do it inbetween zero crossings. This way I avoid discontinuities and the signal is clean. So I introduced some self-regulating mechanisms that modify the process in between ZCs. Code and some examples are here
{function: comment, function: intention, keywords: [memory, presence, past, segmentation, zero crossing]}
non real space
One idea is: creating a second process, that is completely decoupled from the acoustic environment (no mircophone input), but whose output is perceptually similar to the one generated by the coupling of the staircase with the original resonator. These two processes should be similar in timbre but dissimilar in how they behave in time, so to create a sort of fissure between the pysical space and the sound that it's heard. To do this, I duplicated the original feedback delay network, removed the microphone input and added an internal compression mechanism that allows the resonator to enter and leave states of self oscillation autonomously.
{function: comment, function: experiment, keywords: [resonance, staircase, model, reverberation, fdn, prototype, distance, decoupling, fissure]}
So now I have the feeling things are slowly ;) converging to a (sort of) more defined direction, for what concerns my segment. In my previous experiments I was playing around with the idea of resonance, trying to relate the acoustic properties of the Kunsthaus staircase - and the sound events that happen in this site - with a reverberation model based on feedback delay networks.
In the audio examples I posted here sound events happening in the staircase were exciting the - sort of - reverberator that I built, which in turns could enter in self oscillation, thus affecting the acoustic situation of the space. Nevertheless this relationship is quite direct and trivial and lately I've been searching for strategies for decoupling the two, while at the same time maintaining some of the sound characteristics I find intereseting. In other words, I've been tryig out other types of relations that could make the behavior less predictable.
{function: comment, function: contextual, keywords: [resonance, staircase, model, reverberation, fdn, prototype, distance]}
this is a sort of mockup where I was manually activating or killing different processes. these should then respond to the acoustic situation in the staircase, and I want to find a menaningful way to relate them to my previous resonance experiments. nevertheless I like some sound results here and I think it's a good indication of how my segment might behave
beware of some loud events between 4:00 and 5:30... these are mistakes, not supposed to be sound like that ;)
next time
To summarise, lately I've mainly been occupied with distantiating my segment from the physical space. I guess the next step for me is to integrate these new process with my previous resonance experiments, and try to find a balance between tight relations and more loose situations. I'd like to play with the threshold of plausiility between processes, so that the relationship between the physical space and my intervention becomes a bit opaque.
{hhr, 200508}
The decoupling I find interesting, as I have been thinking a lot about distance as an essential property to think about space. That sometimes a distance or indirection (fissure) is indeed a stronger bond between what is connected, than synchrony.
{function: comment, author: hhr, function: response, keywords: [distance, decoupling, staircase, space]}
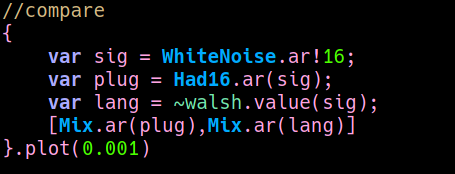
In the original algorithm I implemented, a Hadamard matrix is used to iteratively recombine the sizteen delay lines in order to simulate an ideal room's reflections. A couple of weeks ago I was speaking with Luc Dobereiner and he told me that Hadamard matrices are also used in the Fast Walsh-Hadamard Transform. FWHT is an efficient algorithm to computer the Walsh-Hadamard transform, that is a generalised class of Fourier transforms thorugh which is possible to decompose a signal in a sum of square waves. I didn't know about it and, since it is easy to implement in the time domain, I thought it would be nice to use the same kind of process both for sound processing and analysis. So, following the pseudo code here, I did some tests in SC. What I didn't know is that the Walsh functions ("square waves") used for resynthesis are not ordered according to their pitch (as in Fourier), nor it is easy to determine their timbral characteristics, becasue they can be quite complex. So I had to drop the idea of using the FHWT for analysis purposes, but since the algorithm is much more efficient than the first one I implemented, I reformulated my old reverberator accordingly, that now looks like this
{function: comment, function: contextual, keywords: [algorithm, hadamard, walsh, fdn, implementation]}

poz 22 march 2020
last week I moved this patch to the pi and - unsurprisingly - it was a bit  using SuperCollider server at blocksize 1 is not very efficient there. So I've been thinking how to make everything a bit lighter, since ideally I would like to be able to transport it as much as possible. One idea is to translate part of the process into Faust and produce SuperCollider UGens (I'm thinking especially at the walsh-hadamard transform and the feedback delay network) that I can then integrate into the main program. I was expecting this to be a bit tricky on the pi, but as it turned out it's quite straight forward. Just install Faust, and make sure you have a SuperCollider source code in one of the 5 possible path allowed by the shell script called "faust2supercollider" (or edit the path there). This script generates 2 files: a .so file, which is the plugin per se, and a .sc file, that is the class for the language. On the pi the .so file is generated correctly, while the .sc file is generated empty. I couldn't identify the reason yet, but this is not a big problem since I can generate it on my laptop and copy it to the pi. Of course, this copy paste works only for the .sc file and not for the plugin. There's also another strategy, to avoid installing Faust on the pi, that is using faust2supercollider on a laptop with the -ks flag, that allows to keep the intermediate C++ source with SC API. Take this code and compile it on the pi. That's enough to know that faust works easy on the pi, I'll go ahead and translate the walsh transform in a ugen - and learning Faust on the way, since it's my first ride ;)
using SuperCollider server at blocksize 1 is not very efficient there. So I've been thinking how to make everything a bit lighter, since ideally I would like to be able to transport it as much as possible. One idea is to translate part of the process into Faust and produce SuperCollider UGens (I'm thinking especially at the walsh-hadamard transform and the feedback delay network) that I can then integrate into the main program. I was expecting this to be a bit tricky on the pi, but as it turned out it's quite straight forward. Just install Faust, and make sure you have a SuperCollider source code in one of the 5 possible path allowed by the shell script called "faust2supercollider" (or edit the path there). This script generates 2 files: a .so file, which is the plugin per se, and a .sc file, that is the class for the language. On the pi the .so file is generated correctly, while the .sc file is generated empty. I couldn't identify the reason yet, but this is not a big problem since I can generate it on my laptop and copy it to the pi. Of course, this copy paste works only for the .sc file and not for the plugin. There's also another strategy, to avoid installing Faust on the pi, that is using faust2supercollider on a laptop with the -ks flag, that allows to keep the intermediate C++ source with SC API. Take this code and compile it on the pi. That's enough to know that faust works easy on the pi, I'll go ahead and translate the walsh transform in a ugen - and learning Faust on the way, since it's my first ride ;)
{function: comment, function: intention, date: 200326, keywords: [porting, implementation, faust, SuperCollider, optimisation]}
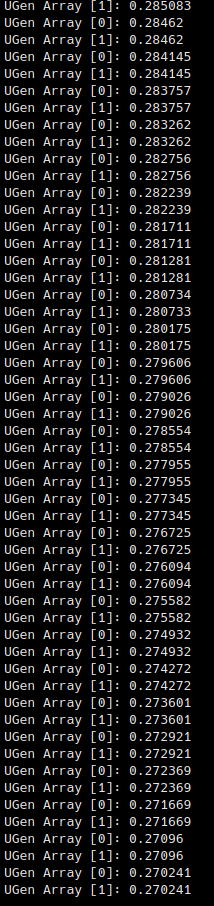
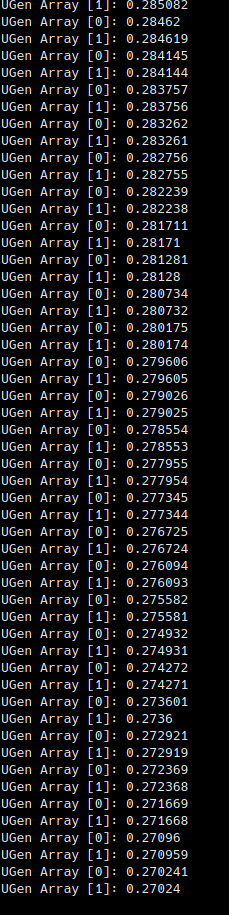
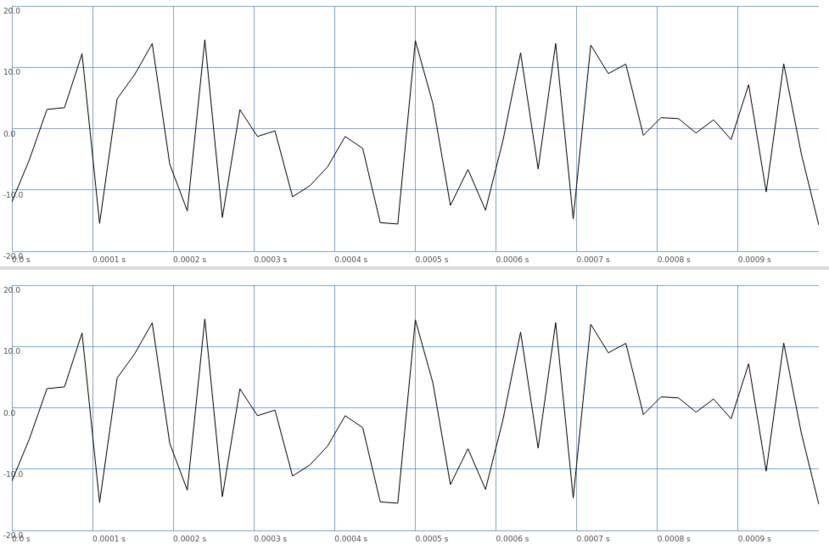
but when I embed the Ugen in the process I get slightly different results. I'd like to understand the reason. Here two recordings. In the first one the matrix is implemented as sc function, in the second one sc ugen. The process is completely deterministic, so there should be no difference in sound outcomes.
code is here
plugin is here
{function: comment, date: 200326, function: test, keywords: [algorithm, hadamard, walsh, fdn, implementation]}
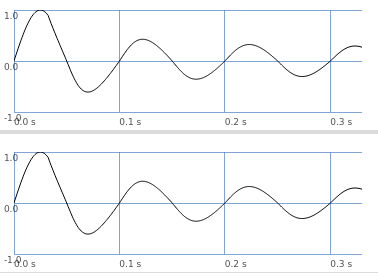
First test translating the hadamard matrix into a Ugen. Doesn't make a big difference in terms of CPU usage (~3-5%) but it's just a small part of the program. Tranlation seems to be correct to the sample:
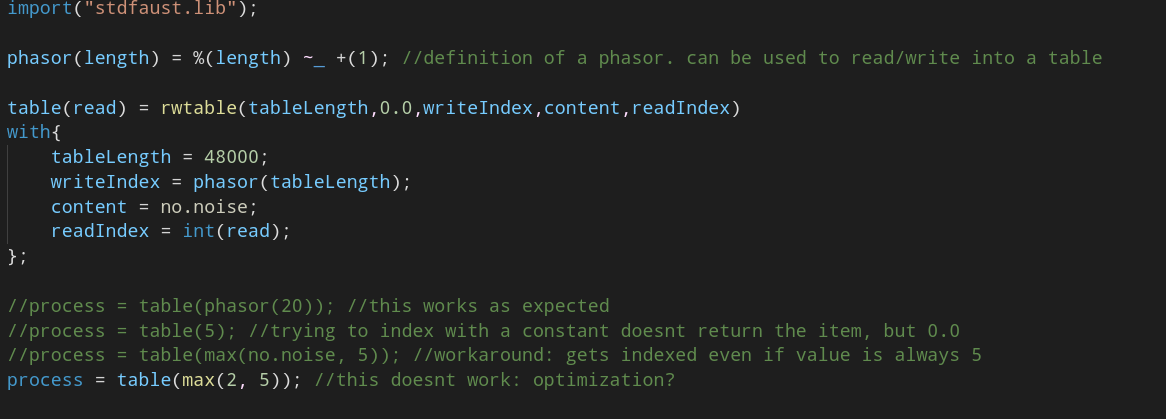
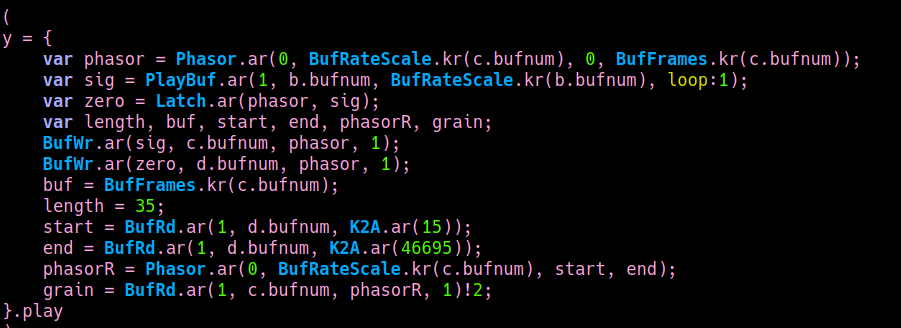
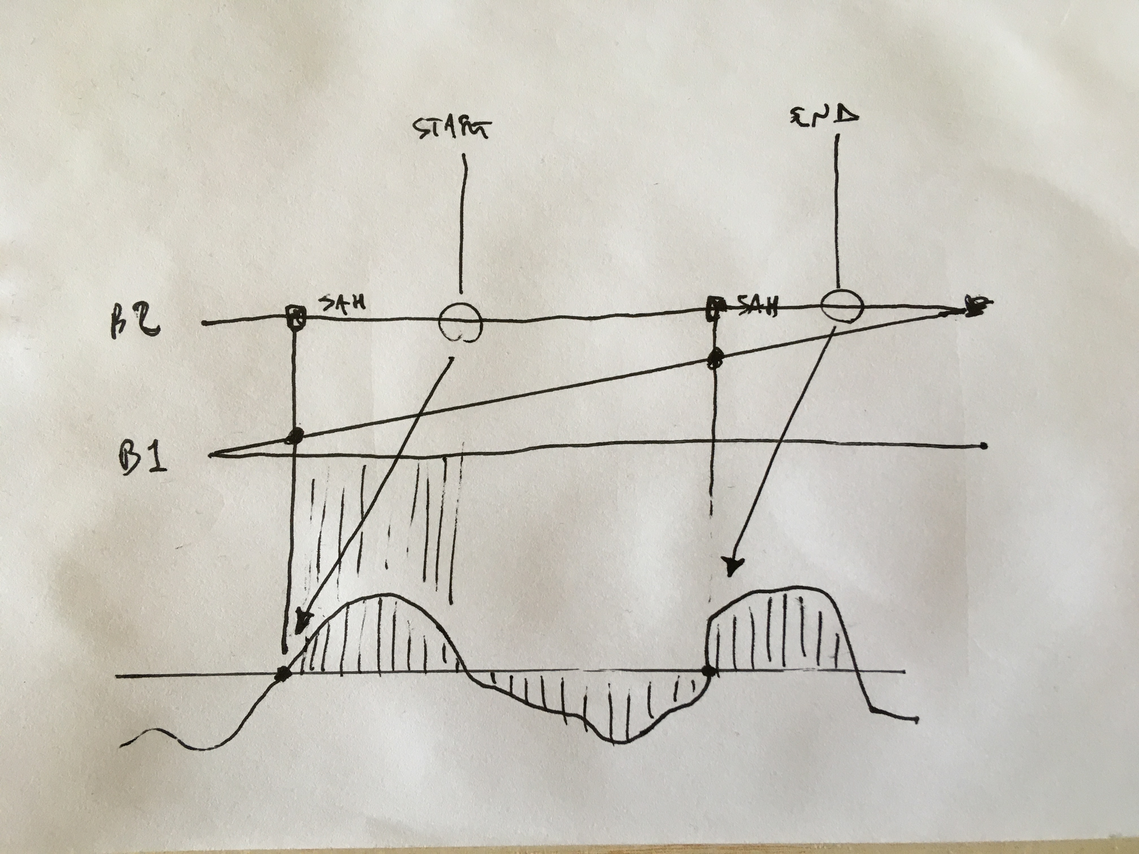
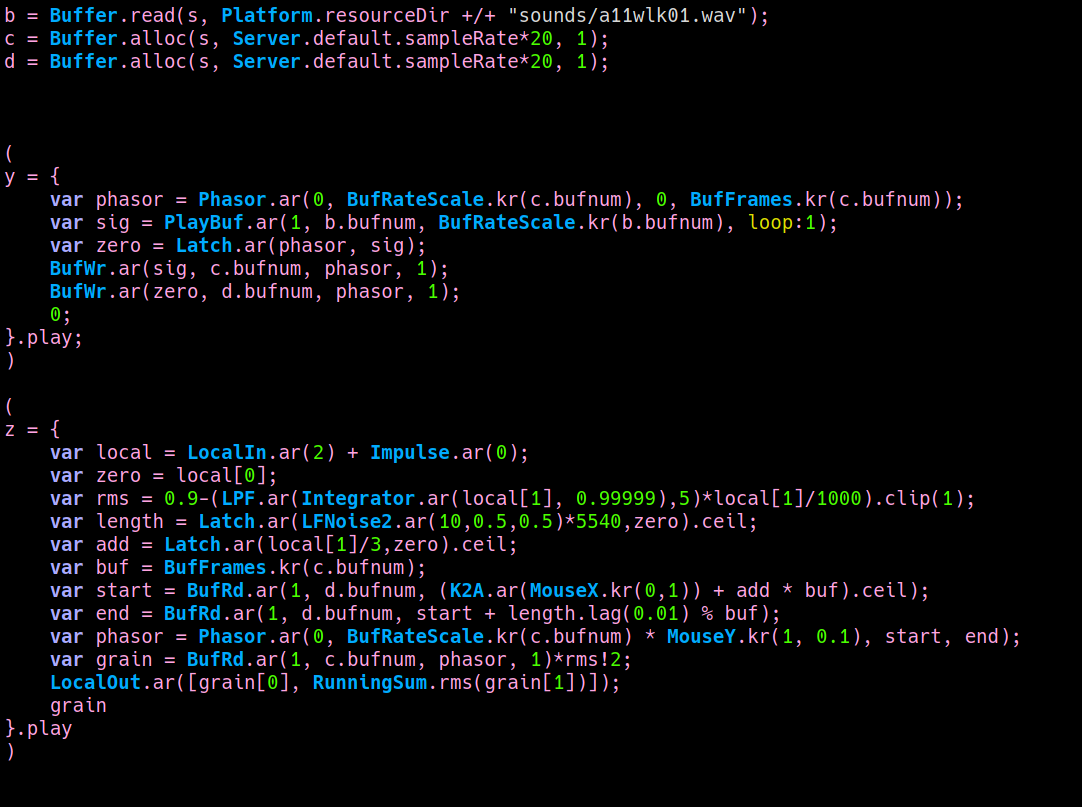
in this way, it is possible to playback snippets of the sampled input signal without using any envelope. just start and end reading at indexes where a zero crossing happens. in the sc implementation, given a position and a desired duration for the snippet, the most close corresponding zero crossing indeces will be used to start / end the playback. this is the faust implementation, using a faust primitive called rwtable:
I didn't find any valid alternative to the rwtable primitive in faust. anyway, through the workaround of creating a constant signal with a max() primitive, this works. Compiling to a SC ugen it saves me around 11-12% of CPU usage.
Folder containing code snippets of this post is here
poz 10 april 2020
small update regarding the process of porting sc code into faust. I ran into a couple of issues that I think are related to the process of optimisation that happens in compilation.
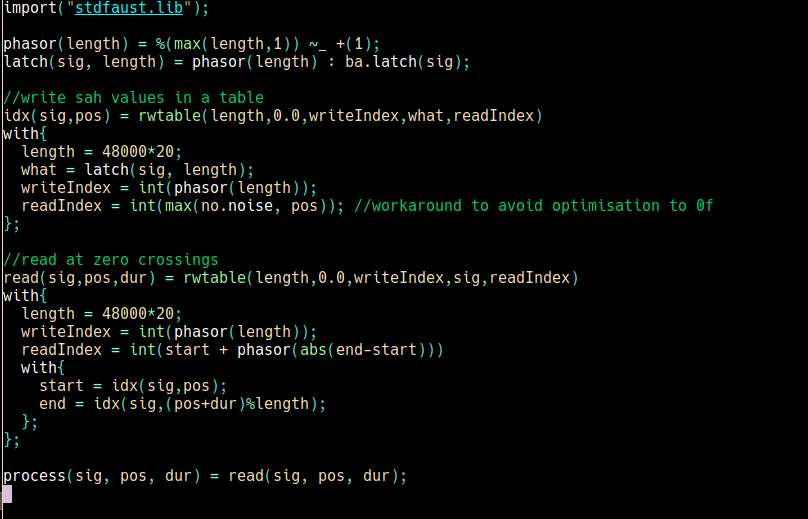
Yesterday, for example, I was trying to translate this sc block into faust:
{function: comment, keywords: [porting, implementation, faust, SuperCollider, optimization]}
what this does is essentially
1. sampling a signal into a buffer and
2. sampling the value of the phasor which is used to write into the first buffer into another buffer. A new phasor value is sampled (and hold) whenever a zero crossing happens in the input signal
in this implementation, I need to read values from the zero crossing table in order to retrieve valid zero crossing indeces to play back from the buffer where I'm sampling the input signal. in the rwtable primitive the last argument is the reading index. So I expected to be able to access values by directly indexing here with integers. It turns out it's not possible: when trying to index with an integer, the primitive always returns 0.0 if I substitute this by some form of "signal", even if the signal is constant, this works as expected. I suspect this is a bug that results out of the optimization process...
try a reproducer here
I tried to trace back the cause of this small discrepancy between the
two, but I wasn't yet able to find it. Anyhow, given that the
difference is very small and that in the last version the sound result
is very similar, I think I can accept this "approximated version".
I decided that whenever I find an element whose implementation
'matters' for my copmpositional habits I'll add it to this faust
library I'm writing, which is essentially a porting of some SC ugens, approximated as close as possible
What I tried next was to manually insert the offset in the Faust code,
reaching an even closer approximation. This small details produces a temporal behavior which I is much closer to the original.
Initially I began translating Supercollider code into Faust mainly for
efficiency reasons (to run code that I couldn't run on the Pi). Given
that the processes I use mostly rely on tiny details, I'm trying to do
the most accurate porting I can (ideally 1:1, at sample
level). Sometimes this is possible, other times I have to accept a
very close approximation. What I find interesting is that at times
such approximations have little to no effect on the sound forms that
are generated, whlie other times they can have a greater effect,
exposing the influence of implementation itself on the overall
dynamics of a system. In this sense, the process of translation might
also be seen as an alternative method to identify those elements, or
their smaller constituent parts, that play a central role in
generating those processes I'm interested in.
In the case above, the translation of the Supercollider Compander is
an example of how the smallest difference in such approximations can
alter the dynamics of a feedback process.
In my first implementation I could write a compressor that's almost
identical to the one which is part of the supercollider
plugins. Namely, it is identical except for a very tiny offset of ~
-0.00000111 (that I couldn't find where it comes from) when computing
the next gain value. This small difference produces a radically
different behavior.
{poz, 24-Apr-2020}
on process, translation, approximation and smallest difference
generally I'm interested in composing sets of relationships that
create the conditions for the emergence of aeshtetics forms that I
find interesting. Processes that can stimulate my interest are usually
characterised by sound qualities that reflect my aesthetic
preferences, but they also need to posses another, more opaque
property: namely, they need to have /someting/ I can't explain at
first, some quality that exceeds the expectations I had at the time of
implementing that specific set of relationships. Something that grabs
my attention and makes me curious to investigate where this excess
comes from, to look for that turning point that emerges out of
algorithmic experimentation and transforms an uninteresing process
into an interesting one.
Many times this turning point is not so easy to trace back and it is
often based on very small differences, tiny changes in the code or
parameters that, when combined, might be hard to
identify. Nevertheless I noticed that this happens mostly in sound
forms in which timbral and temporal developments combine in unusual
ways. For example, what I like in this patch I've been working on is
how this 'metallic' timbre that sounds very natural combines with a
strange temporal behavior in which resonances may appear and disappear
in different timescales.
next_gain(val, thresh, below, above) = ba.if(
val < thresh,
ba.if(
below == 1.0,
1.0,
pow(val / thresh, below - 1.0)
),
ba.if(
above == 1.0,
1.0,
pow(val / thresh, above - 1.0)
)
);
{kind: code}
next_gain(val, thresh, below, above) = ba.if(
val < thresh,
ba.if(
below == 1.0,
1.0,
pow(val / thresh, below - 1.0) + 0.00000111
),
ba.if(
above == 1.0,
1.0,
pow(val / thresh, above - 1.0) + 0.00000111
)
);
{kind: code}
r = {
arg decay = 211.9;
var local = LocalIn.ar(16) + Impulse.ar(0);
var loc = local+local.reverse;
var room = [0.735];
var lengths = [2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53]**room/1000;
var delay = DelayC.ar(loc, 2, lengths);
var walsh = delay;
walsh = walsh * (decay*0.95);
walsh = ~walsh.value(walsh);
walsh = Compander.ar(walsh, walsh, 0.47, 1.0, LPF.ar(delay[1].abs,2)/100, 0.0000015, 3.9);
walsh = walsh.tanh;
LocalOut.ar(LPF.ar(walsh, 20000));
walsh = LeakDC.ar(walsh);
Out.ar(0, Splay.ar(walsh));
}.play;
{kind: code}